Building a human-level Matching algorithm is the most important & the most difficult challenge of the Recruiting and Human Capital software industry.
In this article, we'll outline our approach to AI safety toward Building a human-level Matching algorithm. We'll also share our recent advancements in AI, including the release of our latest Scoring algorithm: a 4-billion-parameter LLM designed for recruiting. We'll cover:
- The Game-changing Impact on Talent Acquisition and Talent Management
- Seamless integration via API or our user-friendly AI Copilots
- Personalization features through the Fine-Tuning API
- How it elevates your compliance efforts
Table of contents
- Overview
1.1. Abstract
1.2. Previous Work
1.3. Model & Datasets - Using Cerebro
2.1. The Algorithms Marketplace
2.2. Creating a Cerebro Algorithm
2.3. Preparing your Dataset
2.4. Making a Scoring API Call
2.5. Estimating Cerebro Costs - AI Copilots
3.1. Cerebro as a Copilot vs. Cerebro as an API
3.2. Talent Copilot
3.3. Recruiter Copilot - AI Studio
4.1. Fine-tuning API
4.2. Preparing your Dataset
4.3. Defining your Conversion Goals
4.4. Launching your Training
4.5. Estimating Fine-tuning Costs - Evaluation & Compliance
5.1. Introduction
5.2. Current Regulatory Landscape
5.3. Compliance-Centric Design
5.4. Training Data Evaluation
5.5. Pre-Deployment Assessments
5.6. Post-Deployment Monitoring
1. Overview
1.1. Abstract
For nearly 30 years, the HR sector has relied primarily on two technologies to address labor market challenges. Yet these technologies present essential limitations:
- Keyword Boolean Search: Falling short in assessing complex human factors such as cultural fit, motivation, growth potential, and social skills (Monster.com was launched in 1994, and CareerBuilder was founded in 1995)
- Roles & Skills Taxonomies: Quickly outdated and failing to cover the full spectrum of skills in a fast-changing job landscape (The US Dictionary of Occupational Titles, first published in 1939)
Since founding HrFlow.ai in 2016, our mission has remained clear: "Solving unemployment, one API at a time.". Our core belief is that Artificial Intelligence is the key to fixing the labor market in 2 ways:
- Enhancing Human Skills Exponentially: AI will amplify human intelligence and physical capabilities, potentially increasing global GDP by 14% or $15 trillion by 2030, according to PwC.
- Matching Talent with Opportunities: According to McKinsey's research, connecting people with the ideal job opportunities can raise global GDP by 3%, equivalent to a $2.7 trillion increase by 2030.
1.2. Previous Work
It's been three years since we launched GemNet 2, the AI algorithm behind our Job and Profile recommendation engine at HrFlow.ai. The iterations of GemNet over the years—GemNet0 in 2016, GemNet1 in 2018, and GemNet2 in 2020—reflect our commitment to achieving human-level job-matching intelligence to solve unemployment one API at a time.
GemNet2 was designed to solve six long-standing hurdles in the Recruiting industry:
- Complexity of Human Factors: Quantifying attributes like cultural fit, motivation, potential for growth, and interpersonal skills.
- Resume Limitations: Predicting hidden transferable skills, soft skills, and nuances.
- Job Description Limitations: Decoding text variability, corporate culture, work environment, realistic requirements.
- Diversity and Inclusion: Mitigating Company's historical data biases and verifying open-source HR datasets.
- Multi-channel Data Integration: Modeling various HR materials beyond the resume, including interview transcripts, portfolios, training records, project annotations, cover letters, performance evaluations, feedback forms, and onboarding documents.
- Mass Hiring: Empowering recruiters when handling large talent pools becomes humanly unfeasible.
Within a year, GemNet2 has been deployed by hundreds of HR Tech vendors (e.g., Talentsoft), Staffing agencies (e.g., Manpower), Recruiting firms (e.g., Gojob), and Large employers (e.g., French Army, Sanofi, Safran, Monoprix) worldwide. During the pandemic, when 300 million were left jobless, and sectors from IT to healthcare had vacant positions, our AI algorithm became the go-to technology for streamlining job placements and tackling HR-driven company evolution and employment challenges.
Groupe Casino ranks as the 7th leading mass-market retail group in France. (Statista.com 2023)
1.3. Model & Datasets
Today, we are incredibly excited to share the next stage of this journey. We are proud to introduce our most advanced AI scoring algorithm yet - Cerebro, a 4 Billion parameters model, expanding our scoring capabilities to 43 languages.
Cerebro represents a significant leap forward in Profile and Job Matching algorithms. Not only has it surpassed all previous performance benchmarks, but it has also outperformed the accuracy, speed, and efficiency of our previous GemNet Algorithm generation.
Cerebro addresses the past issues tackled by GemNet2 and paves the way for a revolutionary era in Talent and Job Marketplaces. This new Scoring Algorithm spotlights six pioneering, data-centric features:
- Labor Market Insight: Seamless integration with online, verified job market data sources to monitor evolving skill demands and role dynamics.
- Trend Projection: Predict the evolution, convergence, and dissolution of job roles and skills in the forthcoming market landscape.
- Company awareness: Recognize the uniqueness of each company and tailor the matching engine accordingly without replicating internal biases.
- Audience-centric: Configure algorithms to resonate with the distinct motivations of various stakeholders - from job seekers and recruiters to employees and hiring managers.
- Live & Collaborative Learning: Evolve with each interaction, mirroring the adaptability of big e-commerce platforms.
- International Compatibility: Integrate insights about cultural distinctions, linguistic diversities, and local job trends.
The default version of Cerebro is trained on an extensive dataset of over 320 billion tokens from Talent and workforce-related fields, covering 43 different languages. This robust training has equipped Cerebro with a remarkable ability to comprehend and process diverse information.
2. Using Cerebro
2.1. The Algorithms Marketplace
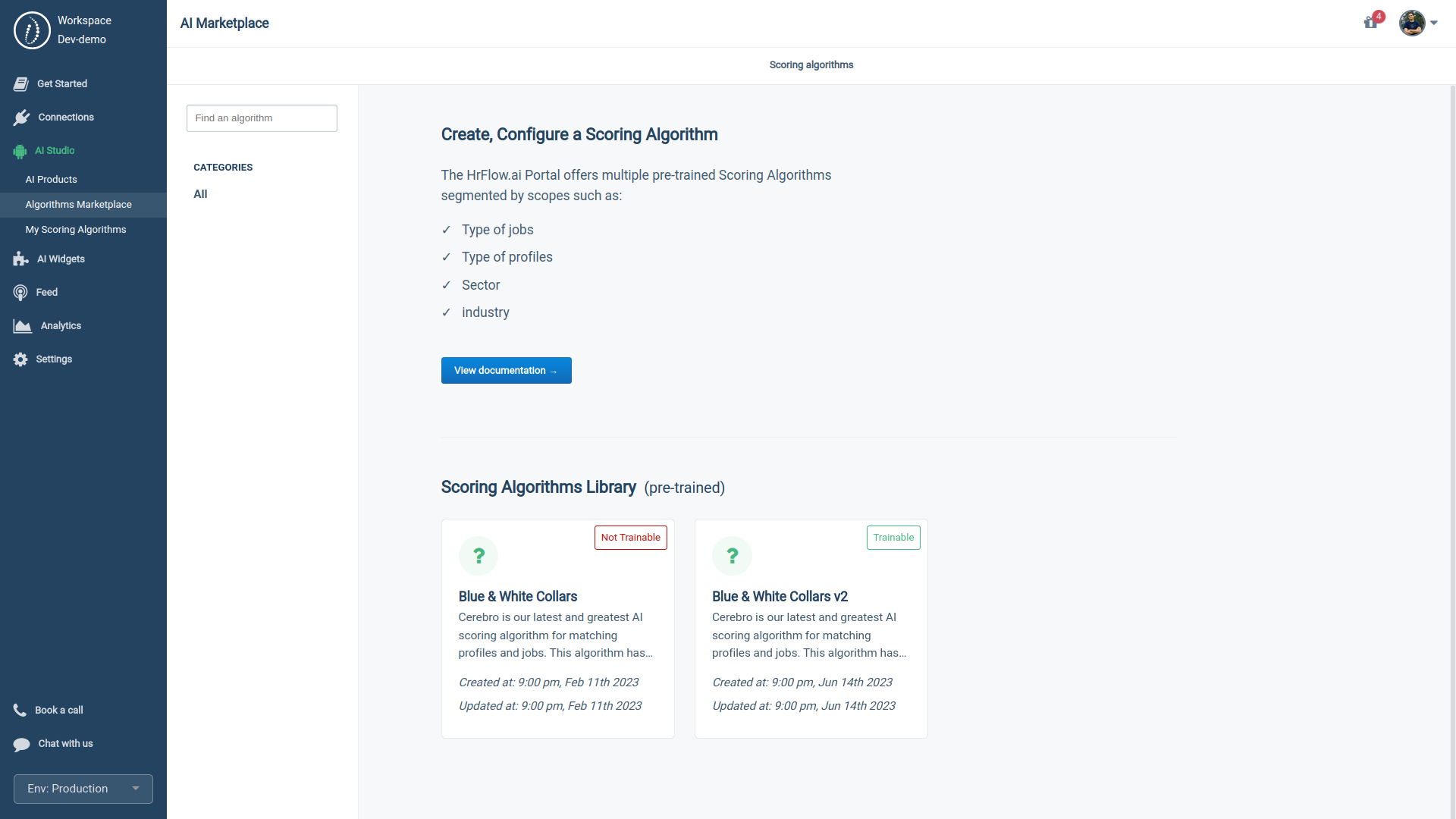
Cerebro is already available in our Algorithms Marketplace under two types:
- Non-trainable: a pre-optimized, non-trainable model that delivers impressive retrieval results immediately. This version best suits cases when you need to score a large-scale database of profiles or jobs (~10M record/index). HrFlow.ai has meticulously pre-trained this model on an extensive Talent and workforce dataset, ensuring efficient Profile and Job scoring "out of the box".
- Trainable: The second type is a retrainable algorithm, which you can fine-tune on the client's unique data. This model allows you to understand better and adapt to the client's specific recruitment preferences and culture and offers a more customized scoring model.
Common use cases:
| Cerebro Non-Trainable | Cerebro Trainable |
|---|---|
| No historical data Needed | Large historical data Optimization |
| Optimal precision and accuracy out-of-the-box | Setting accuracy and precision standards |
| Consistent scoring with zero adjustments | Boosting consistent and reliable scores |
| Designed for straightforward, universal criteria | Correcting deviations from set criteria |
| Handles most standard cases with ease | Managing unusual or outlier cases |
| Ready-to-use for common evaluation needs | Handling complex evaluation challenges |
2.2. Creating a Cerebro Algorithm
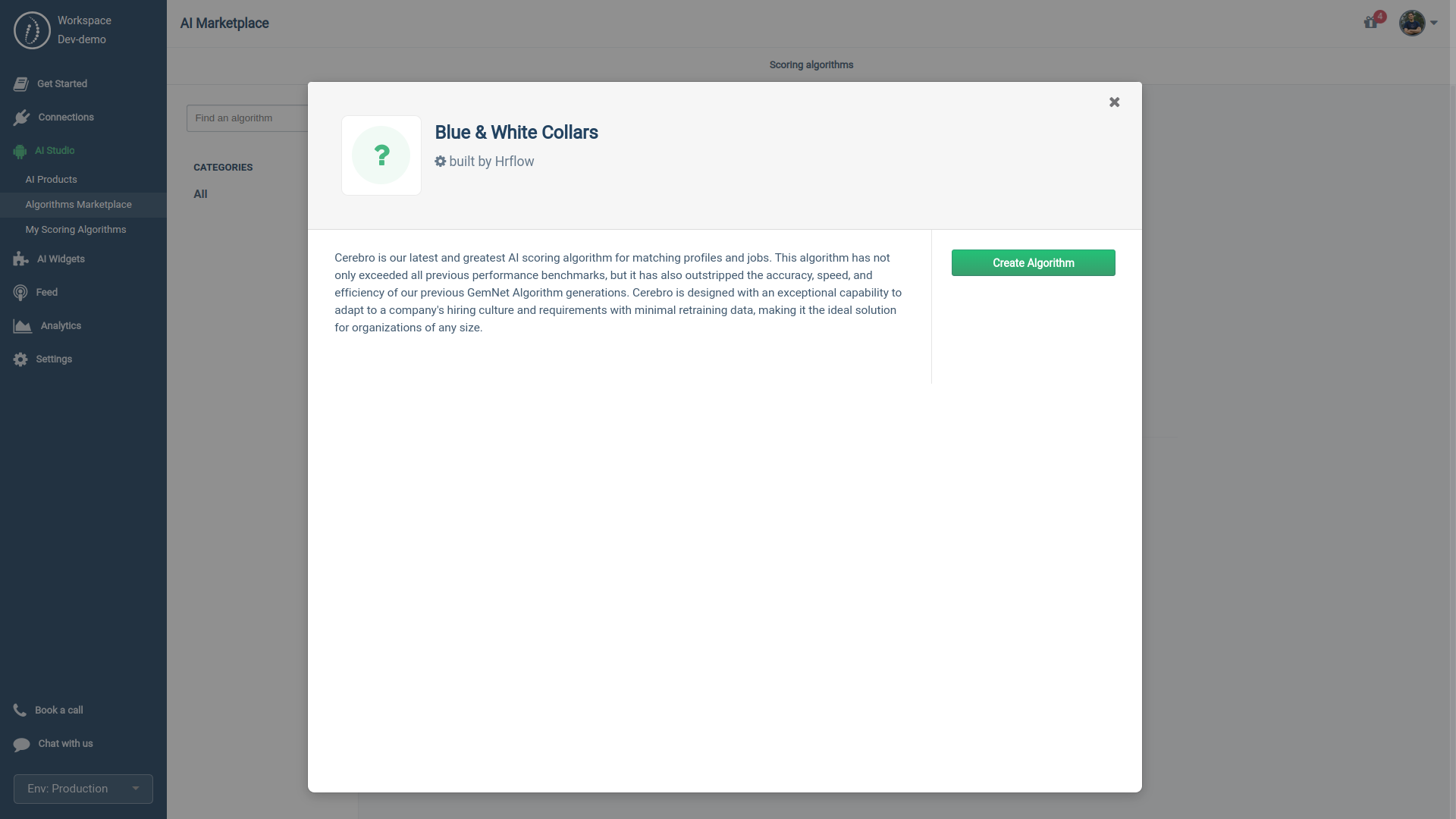
To set up your instance of Cerebro, start by forking (creating a copy) a base model from the Algorithm Marketplace:
- Choose from the Algorithms Marketplace one of the available versions of Cerebro Algorithm
- Fork your algorithm by filling out the setting form:
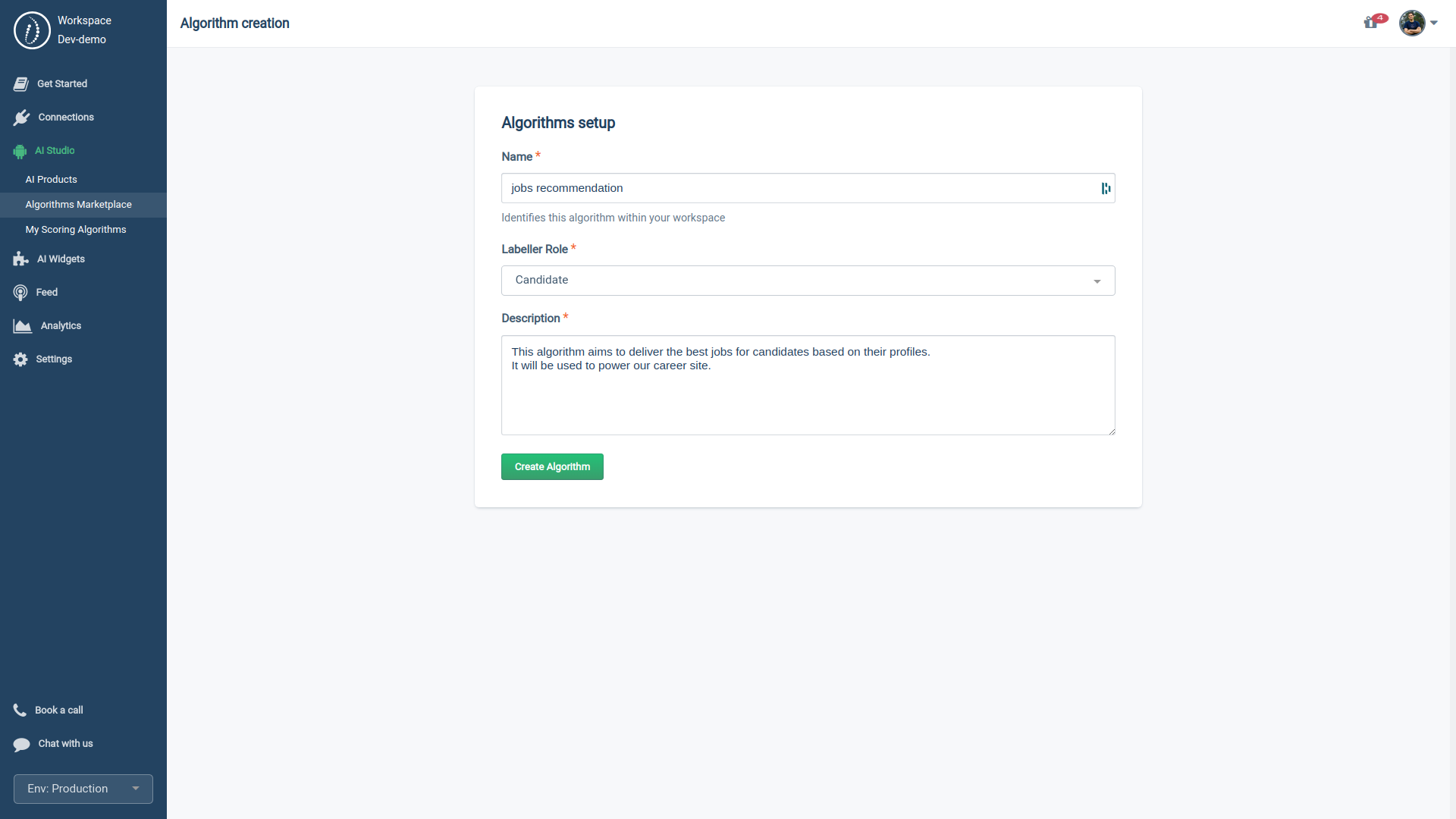
- Name: Label your algorithm copy for easy identification.
Example: "Jobs Recommendation." - Labeller Role: Define the target audience for your algorithm
Options: Candidate, Employee, Recruiter, and Manager. - Description: Elaborate on your algorithm's objective and its application.
Example: "This algorithm is designed to match candidates with the most suitable job opportunities based on their profiles. It's the driving force behind our career site."
2.3. Preparing your Dataset
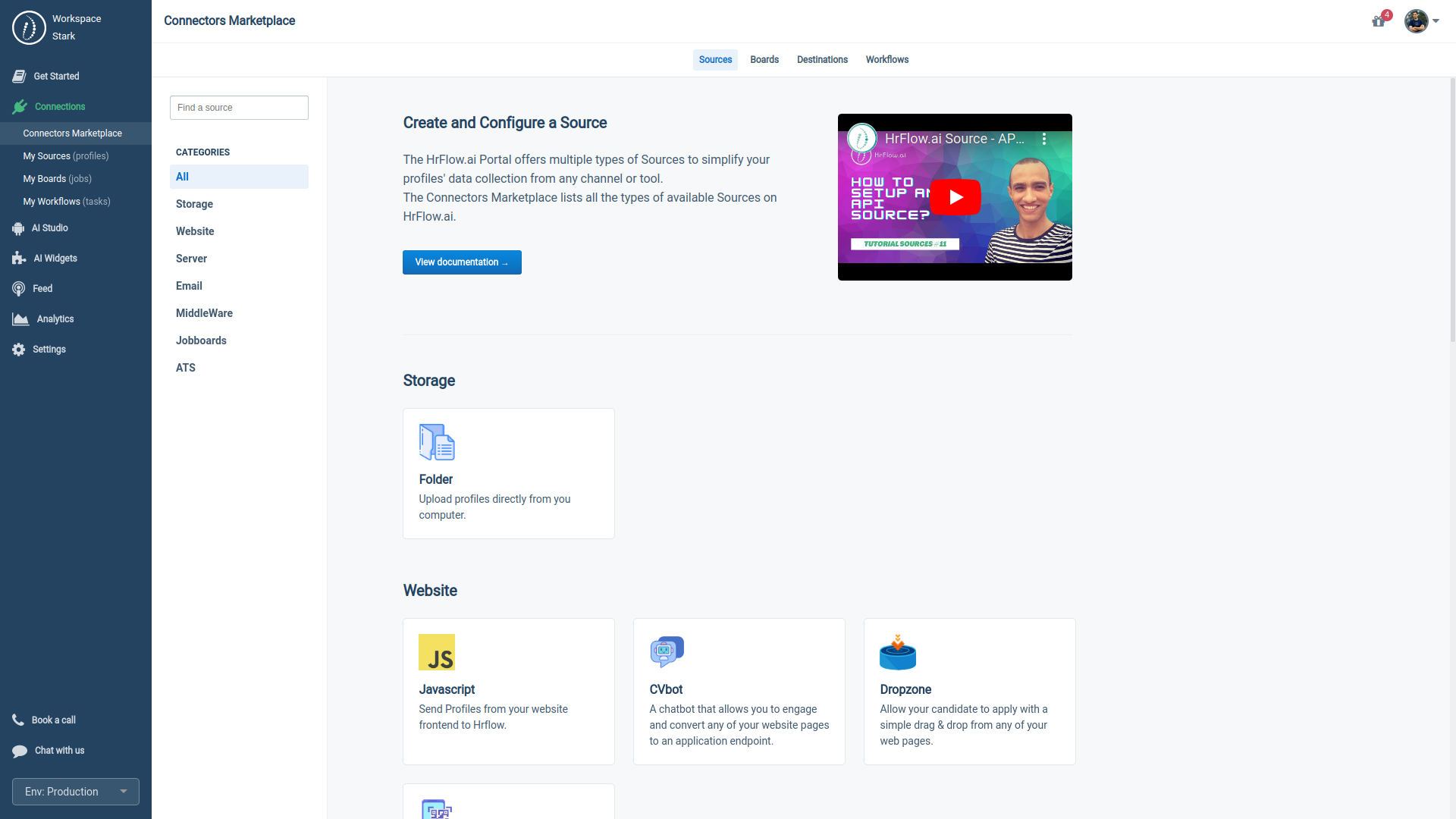
Before scoring your Profiles and Jobs, you must prepare and upload your data into your HrFlow.ai Workspace. You can accomplish this in one of three ways:
2.3.1. HrFlow.ai API Method
- API Endpoints are available on our Developer's Reference.
- Python SDK can be installed using pip install hrflow
- We also offer a Public Postman Collection for convenience.
2.3.2. HrFlow.ai Open-source ETL
- Utilize HrFlow-Connectors to handle the data upload.

2.3.3. HrFlow.ai Automation Studio
- Leverage our No-Code/Low-Code automation interface to pull data from your external data sources into HrFlow.ai seamlessly.
Regardless of the method you choose, you'll need to:
- Parse Data: using Resume Parsing API for Profiles and Text Parsing API for Job Descriptions to structure the Data for the Scoring Algorithm.
- Index Data: using Profile Storing API and Jobs Storing API in the Scoring Algorithm Storage.
2.4. Making a Scoring API Call
Once you've forked your Scoring Algorithm, HrFlow.ai will generate an 'algorithm_key' for you. This key enables you to score both Profiles and Jobs.
After prepping your data as described above, you're set to make your first Scoring API request. The requests are categorized into two types:
- Candidate & Employee Side: Help individuals land their dream job by recommending the most fitting job opportunities using the Jobs Scoring API.
- Recruiter & Manager Side: Assist professionals in hiring top-tier talent that best aligns with the given job description using the Profiles Scoring API.
2.5. Estimating Cerebro Costs
The pricing structure for using the APIs required for Cerebro is organized as follows:
- Parsing APIs incur a charge per transaction,
- Searching and Scoring APIs are billed based only on the number of active stored profiles or jobs, regardless of the number of query requests made
For detailed pricing information, please refer to our help center:
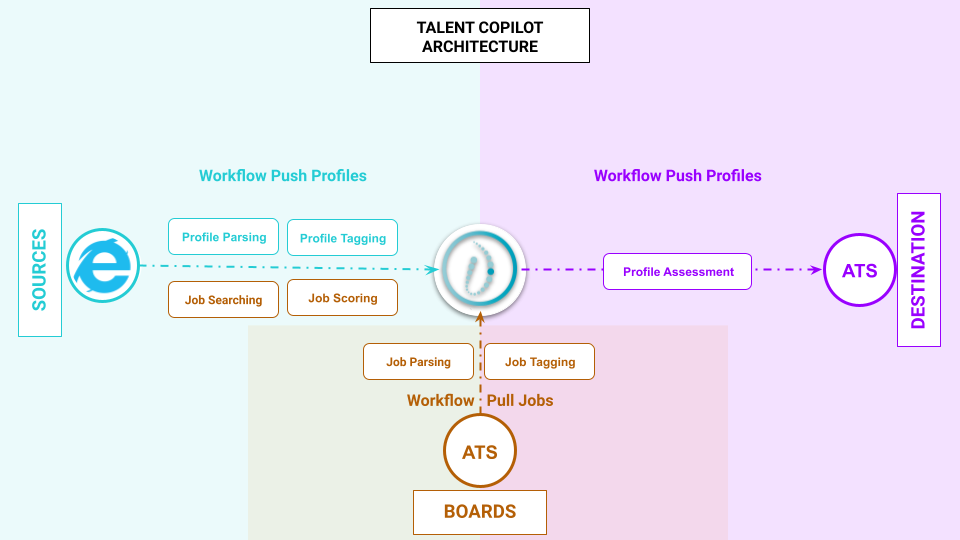
3. AI Copilots
3.1. Cerebro as a Copilot vs. Cerebro as an API
In 2023, APIs stand as the cornerstone of modern software development, offering developers a vast array of possibilities. Yet, when it comes to building an AI-driven user experience from an API, you should consider several factors:
- Time-efficiency: Developing an AI interface isn't a one-day task, particularly when starting from ground zero.
- Multidisciplinary Collaboration: Involving talents from multiple domains, such as backend and frontend development, DevOps, in addition to UX/UI design.
- User-Centric Design: Some users, like recruiters and candidates, have been slower to embrace AI technologies, often due to concerns about AI hype, regulations, and potential misuse. Building trust needs ongoing updates based on user feedback.
- Compliance: adapting the user experience to include location-based algorithmic and privacy consents in line with the continuously evolving regional laws and regulations.
At HrFlow.ai, we have built our expertise over seven years by partnering with
- HR Software Vendors: We are familiar with their limitations, time constraints, and packed product roadmaps, all while they are tasked with delivering value to their customers.
- People-centric Businesses: HR Professionals require fast, scalable solutions to remain competitive in a rapidly evolving labor market.
Today, we're thrilled to introduce a new line of products within the HrFlow.ai suite: the AI Copilots. With AI Copilots, you get seamless access to Cerebro and all our AI modules. Enjoy:
- Hassle-Free Tech
- Business-Ready Solutions
- HR-Endorsed Features
- Built-in Compliance
Our first AI Copilots are:
- Talent Copilot: This User Interface leverages our Jobs Scoring API to deliver a Netflix-like user experience for candidates, job seekers, and employees.
- Recruiter Copilot: Leveraging our Profiles Scoring API to manage large talent pools and profile databases efficiently.
Common use cases:
| Talent Copilot | Recruiter Copilot |
|---|---|
| AI-powered Career site | AI-powered Talent CRM |
| AI-powered Job Board | AI-powered Talent Pool |
| AI-powered Jobs Alert | AI-powered Workforce Planning |
| AI-powered Talent Marketplace | AI-powered CV Library |
Integrating HrFlow.ai Copilots means generating more revenue:
- For HR Software Vendors: Speed up your time-to-market for generative AI solutions.
- For People-centric Businesses: Empower your HR Professionals with AI to enhance performance and efficiency.
3.2. Talent Copilot
The Talent Copilot offers two immediate returns on investment:
- 🏆 2x Conversion Rate: Capture more candidates, employees, and job seekers from your website, mobile, or at a job fair.
✅ The World’s most advanced Parsing and tagging
✅ 200+ HR Data Connectors - 🏆 5x Matching Rate: Generate more applications/applicants and relevant job recommendations to job seekers and employees.
✅ World’s most advanced Searching & Scoring
✅ Ai-powered image generation
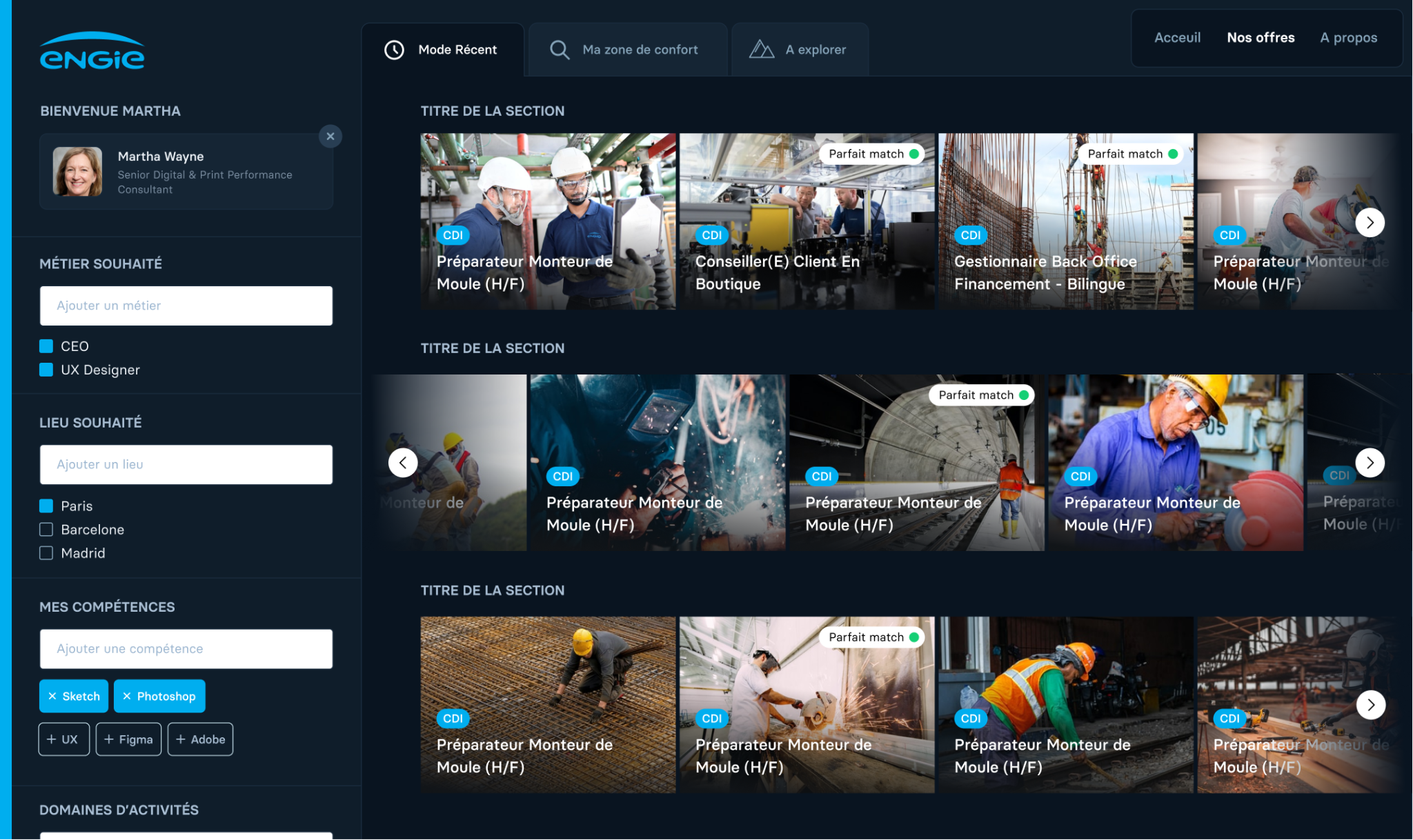
3.2.1. Generating a Talent Copilot
HrFlow.ai enables you to create multiple versions of Talent Copilot to suit your use cases. If you're a recruiter, you might consider generating distinct versions to:
- Tailor the user experience to distinguish between external candidates and internal employees, who may view different job descriptions.
- Customize the design according to your subsidiaries' unique job data and branding.
The following AI modules must be activated to generate a Talent Copilot from your HrFlow.ai Workspace:
| Job API | Profile API |
|---|---|
| Job Imaging ✅ | Ø |
| Job Parsing ✅ | Profile Parsing ✅ |
| Job Searching ✅ | Ø |
| Job Scoring ✅ | Ø |
To generate a Talent Copilot, you need to follow these steps:
- Name: Label your Talent Copilot for easy identification.
Example: "Job site." - Source of Profiles: Select a connector where your profiles will be Uploaded.
Options: Dropzone with Resume Parsing, Linkedin Apply, Voice, Form, and more. - Boards of jobs: Select a list of connectors where your jobs are stored.
Options: ATS, Career site Crawler, and more. - Scoring algorithm: Select the algorithm that will rank the selected jobs based on the imported profile.
Example: "Trainable Cerebro for candidate audience" - Design Requirements: Personalize the text and corporate branding elements on your Welcome Page, Job Listing, and Individual Job Pages.
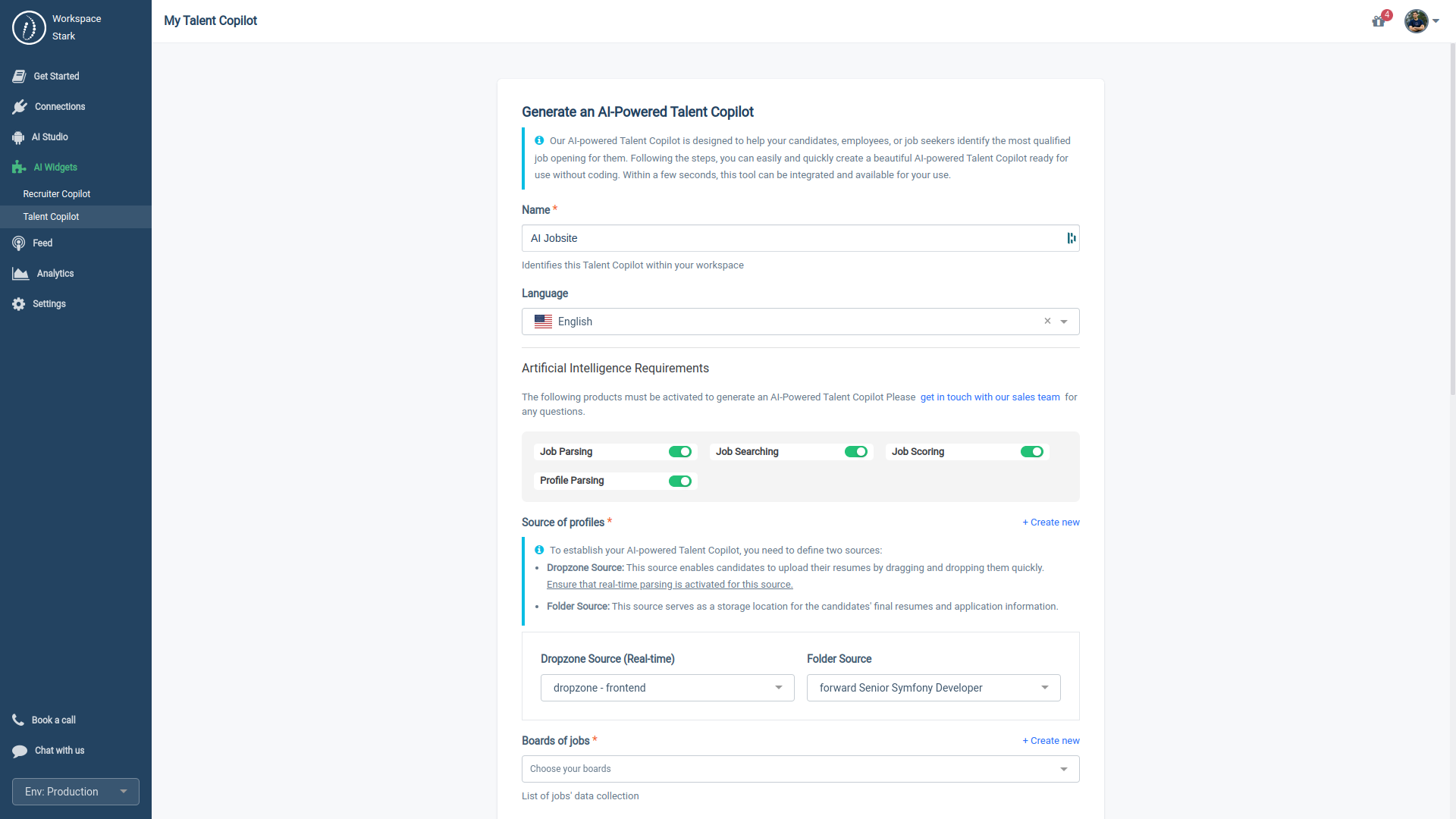
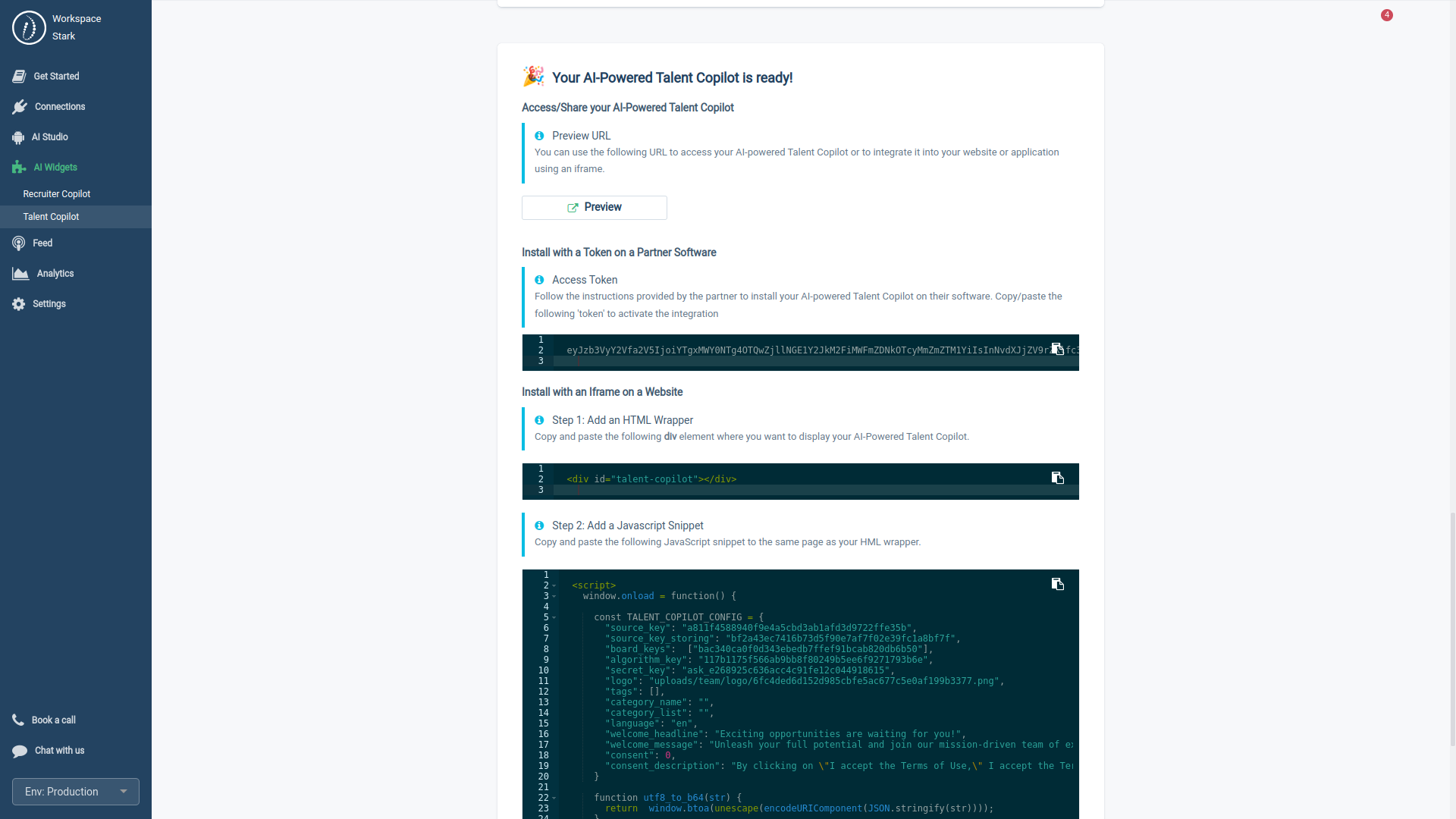
3.2.2. Deploying a Talent Copilot
Once your Talent Copilot is ready, there are two methods to integrate it into your app or website:
- iFrame: Utilize the pre-signed URL or PIXEL.
- Access Token: Choose this option if you're using an app that partners with HrFlow.ai.
3.2.3. Trying the Talent Copilot
To test out Talent Copilot without the need to sign up, visit the link provided below and follow these two steps:
- Upload a test resume.
- Select from one of our public job collections.
Example: "Job board - World - 27187 offers"

Talent Copilot Public Demo
3.3. Recruiter Copilot
The Recruiter Copilot offers two primary returns on investment:
- 🏆3x Hidden Gem: Effortlessly reveal hidden talents in your entire active and past applicant pool with AI, often missed by conventional keyword searches.
✅ World’s most advanced Searching & Scoring
✅ Explainable AI (XAI) with Upskilling - 🏆2x Less Time to Staff & Fill: Unlock new business opportunities by connecting your talent pools with internal and external job positions.
✅ AI-alignement with your culture
✅ 200+ HR IS Connectors
3.3.1 Generating a Recruiter Copilot
HrFlow.ai allows you to create multiple versions of the Recruiter Copilot to fit various needs. As a recruiter, you could create specialized versions for:
- Candidates who have applied for specific roles
- Unsolicited applicants
- Employees interested in changing roles
- Talent & Workforce Data segmentation by department or subsidiary
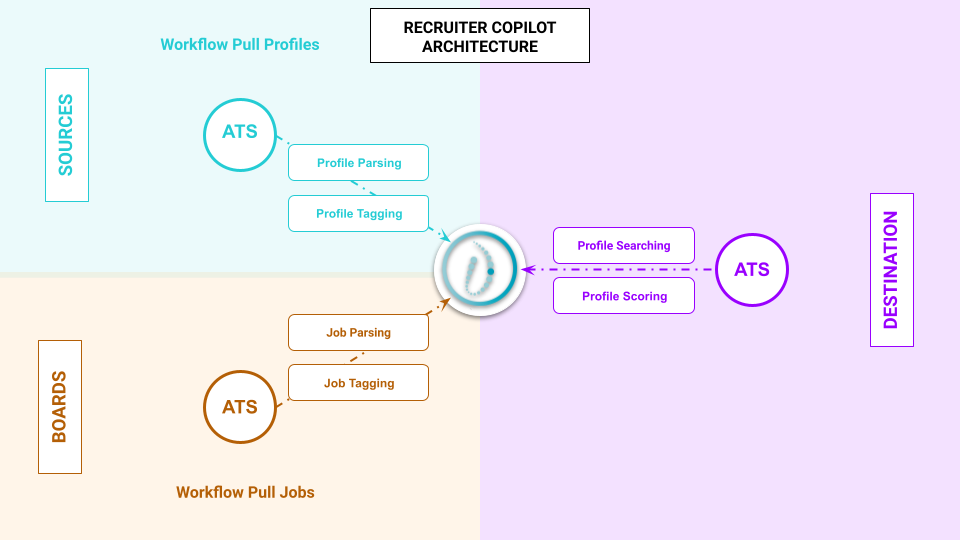
To create a Recruiter Copilot from your HrFlow.ai Workspace, you'll need to enable the following AI modules:
| Job API | Profile API |
|---|---|
| Job Parsing ✅ | Profile Parsing ✅ |
| Ø | Profile Searching ✅ |
| Ø | Profile Scoring ✅ |
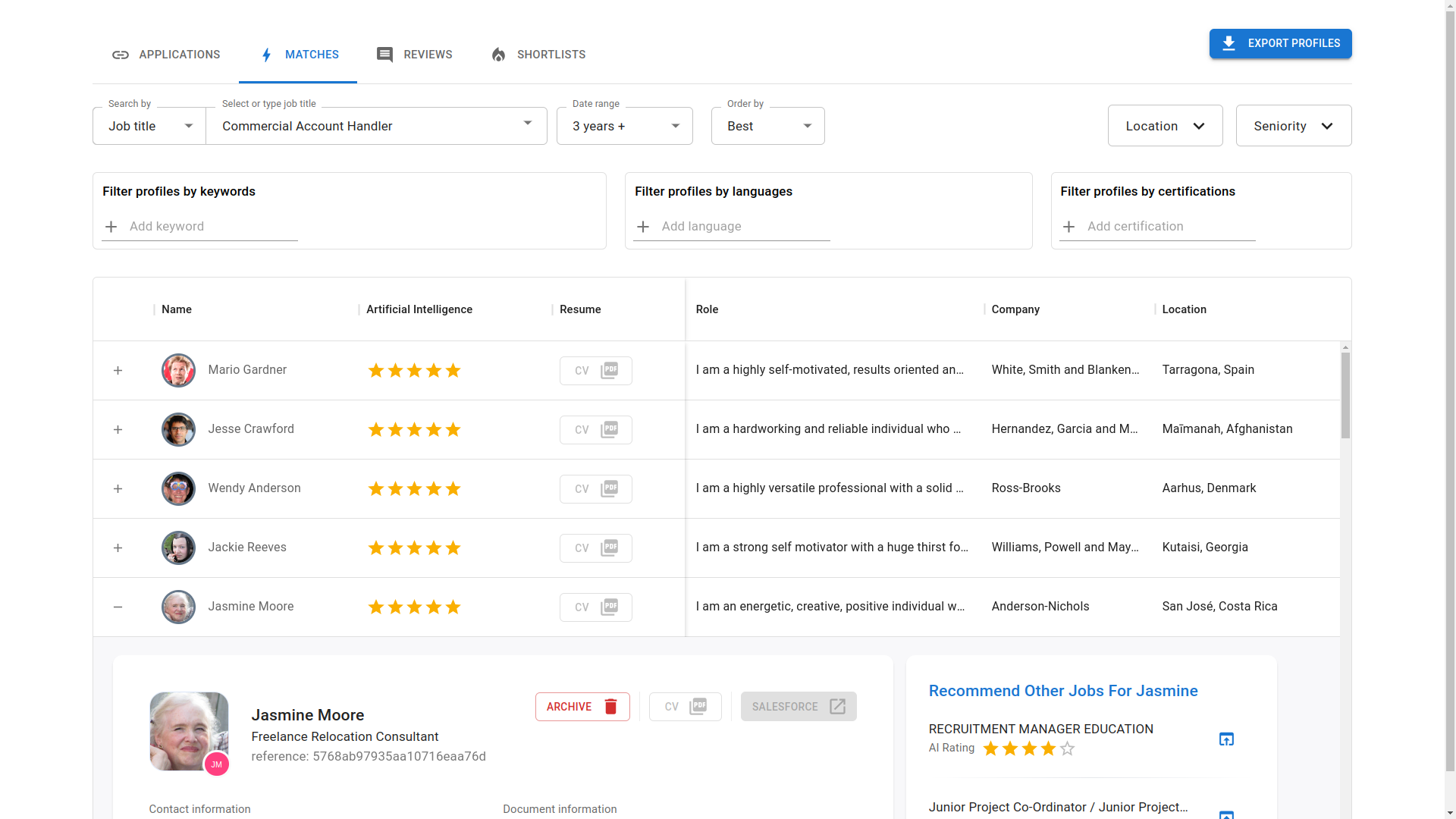
In order for you to generate a Recruiter Copilot, you need to follow these steps:
- Name: Label your Recruiter Copilot for easy identification.
Example: "My Talent Pool." - Sources of Profiles: Select a list of connectors where your profiles' data is stored.
Options: ATS, HCM, CRM, ERP, and more. - Boards of jobs: Select a list of connectors where your jobs are stored.
Options: ATS, Career site Crawler, and more. - Scoring algorithm: Select the algorithm that will rank the selected profiles based on a selected job.
Example: "Trainable Cerebor for recruiter audience" - Design Requirements: Customize search filters, data columns using Tags and Metadata, and the selection process to align with your integrated platforms like ATS, HCM, CRM, and ERP.
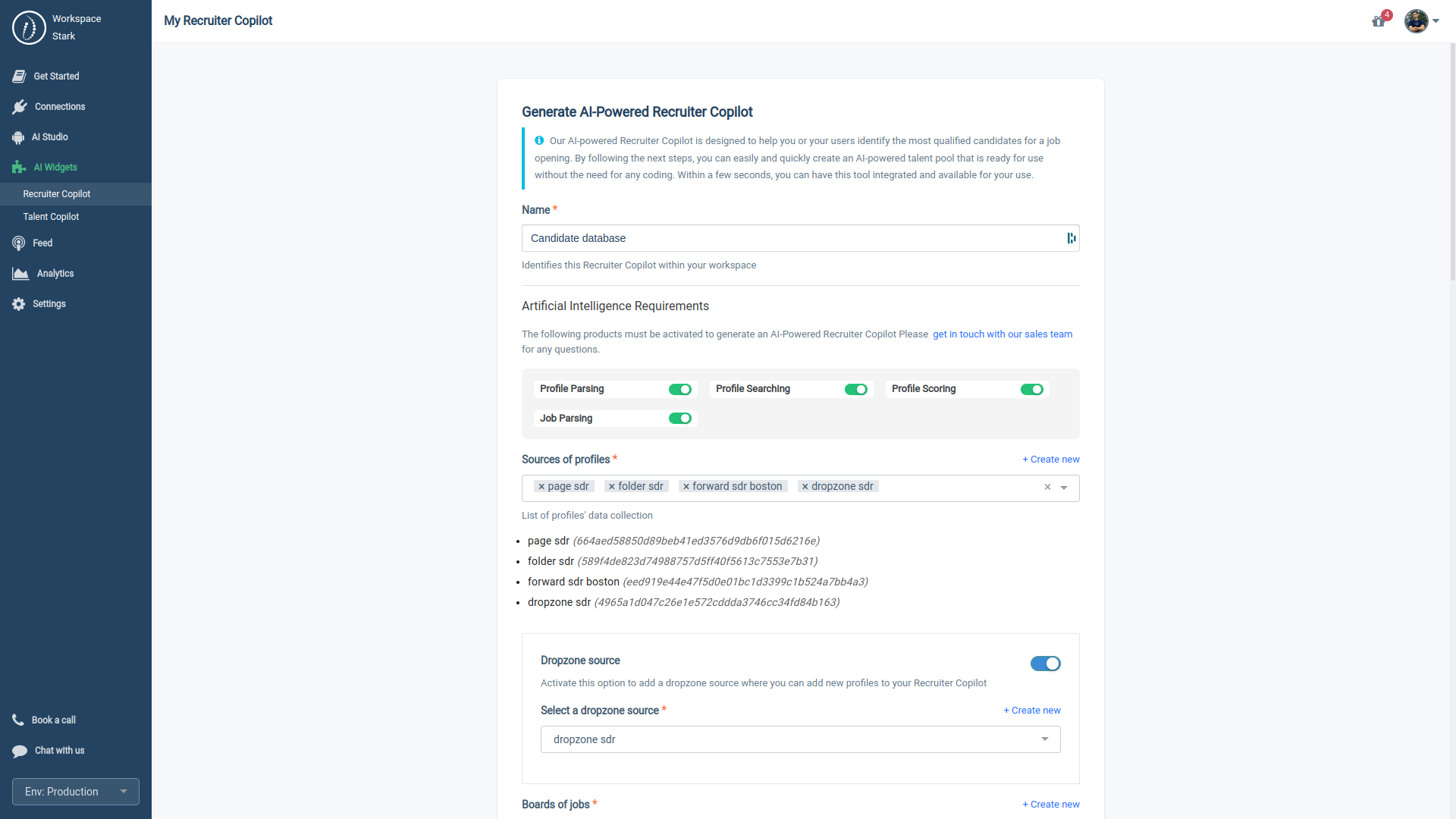
3.3.2. Deploying a Recruiter Copilot
Similar to the Talent Copilot, you can deploy the Recruiter Copilot using one of two methods:
- iFrame: Utilize the pre-signed URL or PIXEL.
- Access Token: Choose this option if you're using an app that partners with HrFlow.ai.
3.3.3. Trying the Recruiter Copilot
To try Recruiter Copilot without signing up, click on the link below and complete the following two steps:
- Enter a Job Title and a Job Description
- Please Select from one of our fake profile collections

Recruiter Copilot Public Demo
4. AI Studio
4.1. Fine-tuning API
What truly sets Cerebro apart is its unique capability to adapt to any company's hiring culture and requirements with minimal retraining. This flexibility makes it an ideal solution for organizations of all sizes, catering to their specific needs and demands.
At a high level, fine-tuning involves the following steps:
- Preparing and uploading training data
- Defining your Conversion Goals
- Training the new fine-tuned model
4.2. Preparing your Dataset
After you've determined that fine-tuning is the next step for you—meaning you've maximized the performance of the non-trainable version of Cerebro and pinpointed areas where it falls short for your specific needs—it's time to prepare your training data.
Being Audience-centric, Cerebro can be retrained according to various conversion objectives, tailoring its performance to meet the unique interests and user journeys of distinct groups:
| Audiences | Definitions | Event Types | Connectors |
|---|---|---|---|
| Candidates | Job seekers navigating job or career sites |
Job views, Apply buttons, Form submissions, Email clicks, etc. |
Pixels, Heatmaps |
| Employees | Individuals looking to transition to a different role within their organization |
Training completions, Performance reviews, Meeting attendances, etc. |
Pixels, App Analytics, API, ETL |
| Recruiters | People responsible for searching and interviewing both candidates and employees for positions |
ATS stages, HCM stages, Interviews |
Pixels, ATS, HCM, CRM, API |
| Managers | People responsible for supervising and guiding employees post-hire |
Job interviews, Performance reviews, Team meetings, Project assignments |
Pixels, HCM, CRM, API, ETL |
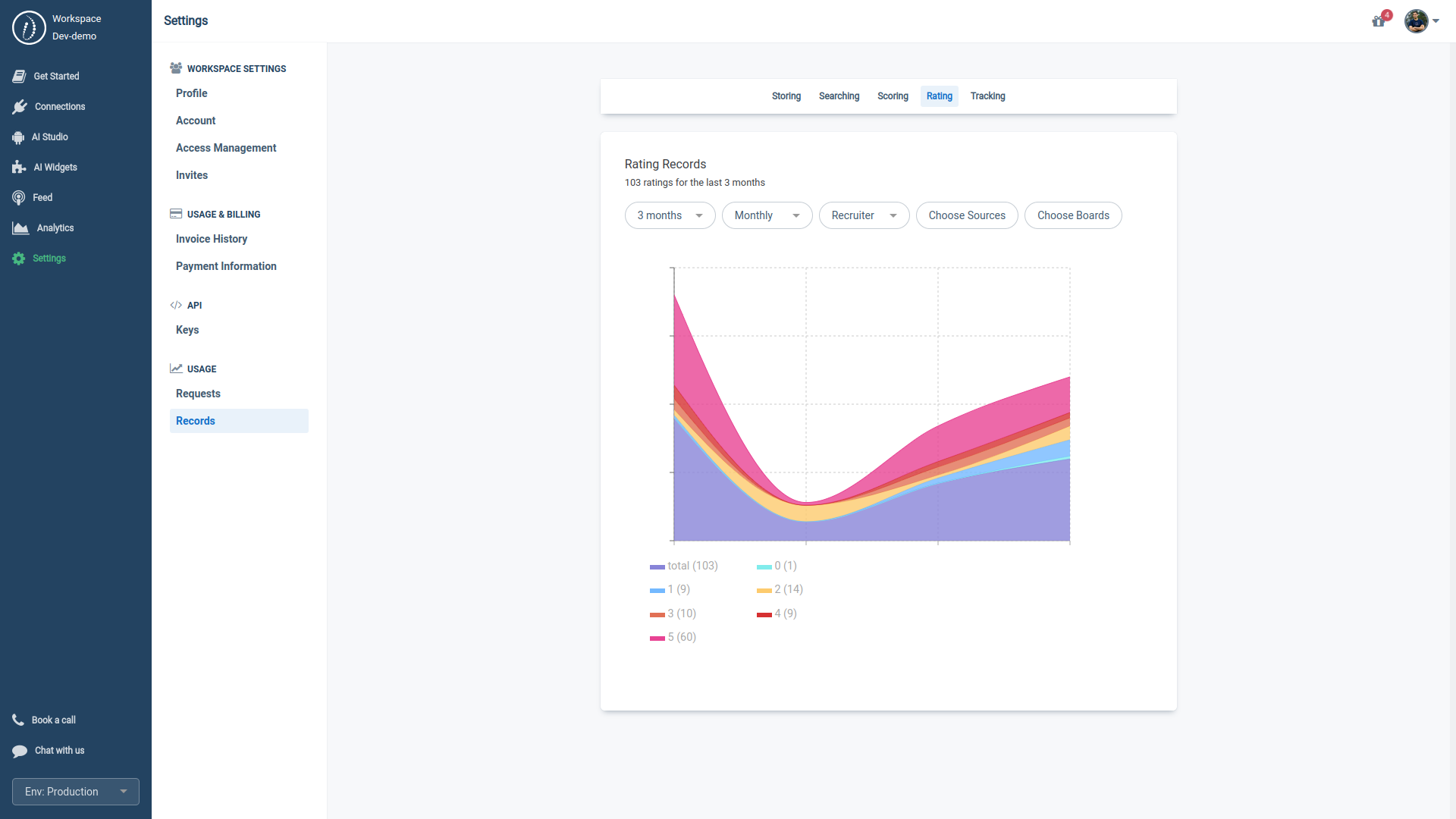
Our Fine-tuning API offers the upload of 2 categories of user feedback:
- Rating API: Upload a 0.00 to 1.00 score to rate a Profile-Job relationship.
- Examples: job reviews and recruiters' evaluations.
- Endpoints: Post a Rating, Get Ratings - Tracking API: Update the status or stage of a Profile-Job interaction.
- Examples: job clicks, ATS stages.
- Endpoints: Post a Tracking, Get Trackings
We've created a step-by-step guide on Github to help you easily upload training data into HrFlow.ai:
 Riminder
RiminderWhen paired with Talent Copilot, Cerebro is retrained in real-time. Candidate interactions with job listings—ranging from views and hovers to applications—serve as a feedback loop.
Similarly, the Recruiter Copilot self-adjusts in real time based on profile ratings from recruiters or hiring managers.
4.3. Defining your Conversion Goals
Once you've synchronized your training data with HrFlow.ai, simply :
- Go to the "My Algorithms" section
- Click on your specific algorithm's name
- Then, Select the "Training" tab
In this tab, you can review your training dataset. HrFlow.ai provides a variety of filters to Calibrate your training data before launching the training process, allowing you to:
- Filter by Sources (or Boards): You can concentrate on a specific talent pool or collection of job roles.
- Adjust the Date Range: Opt to include feedback from a specific period, which can be helpful if your hiring processes or training data have changed.
- Choose the Training Mode: Select 'tracking' or 'rating' based on your available data and training objectives.
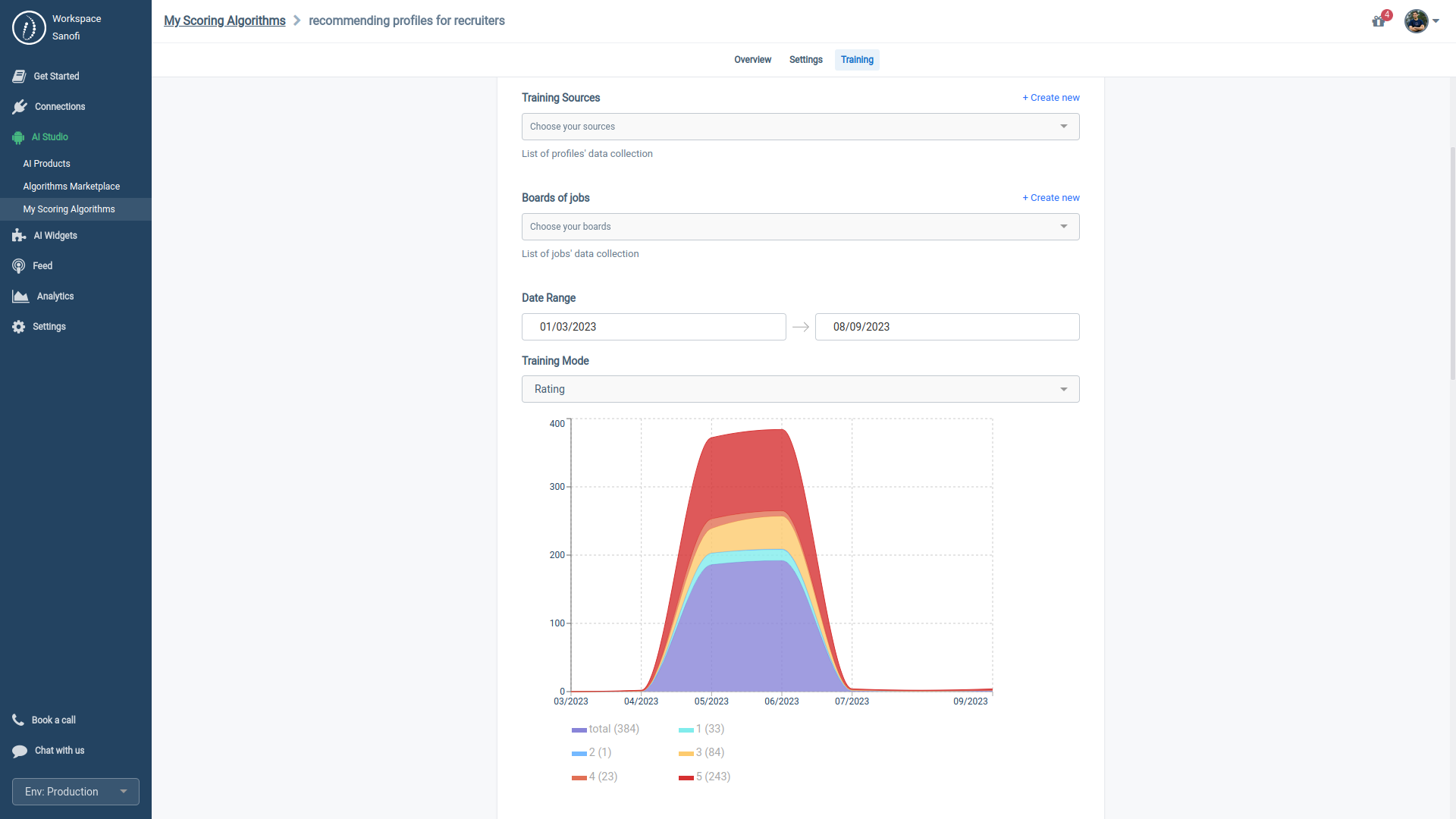
4.3.1. Fine-tuning with Rating mode
If you've chosen the 'rating' as your training mode, feedback with a score above 0.5 will be labeled a positive sample, while scores below 0.5 will be considered a negative sample.
4.3.2. Fine-tuning with Tracking mode
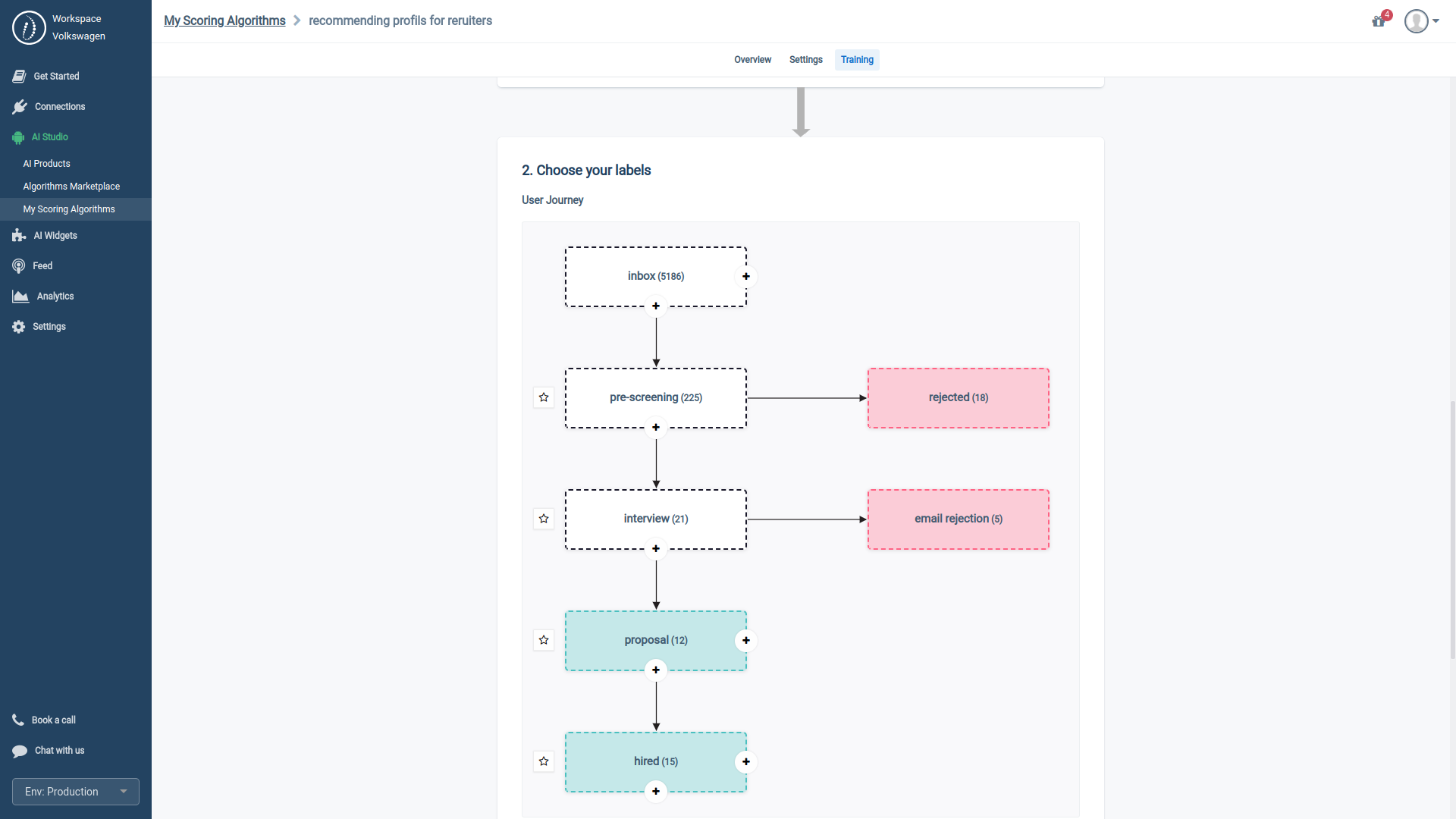
If you select 'tracking' as your training mode, HrFlow.ai lets you map your user journey with our visual builder. This feature allows our Scoring Algorithm to model your process as sequential steps.
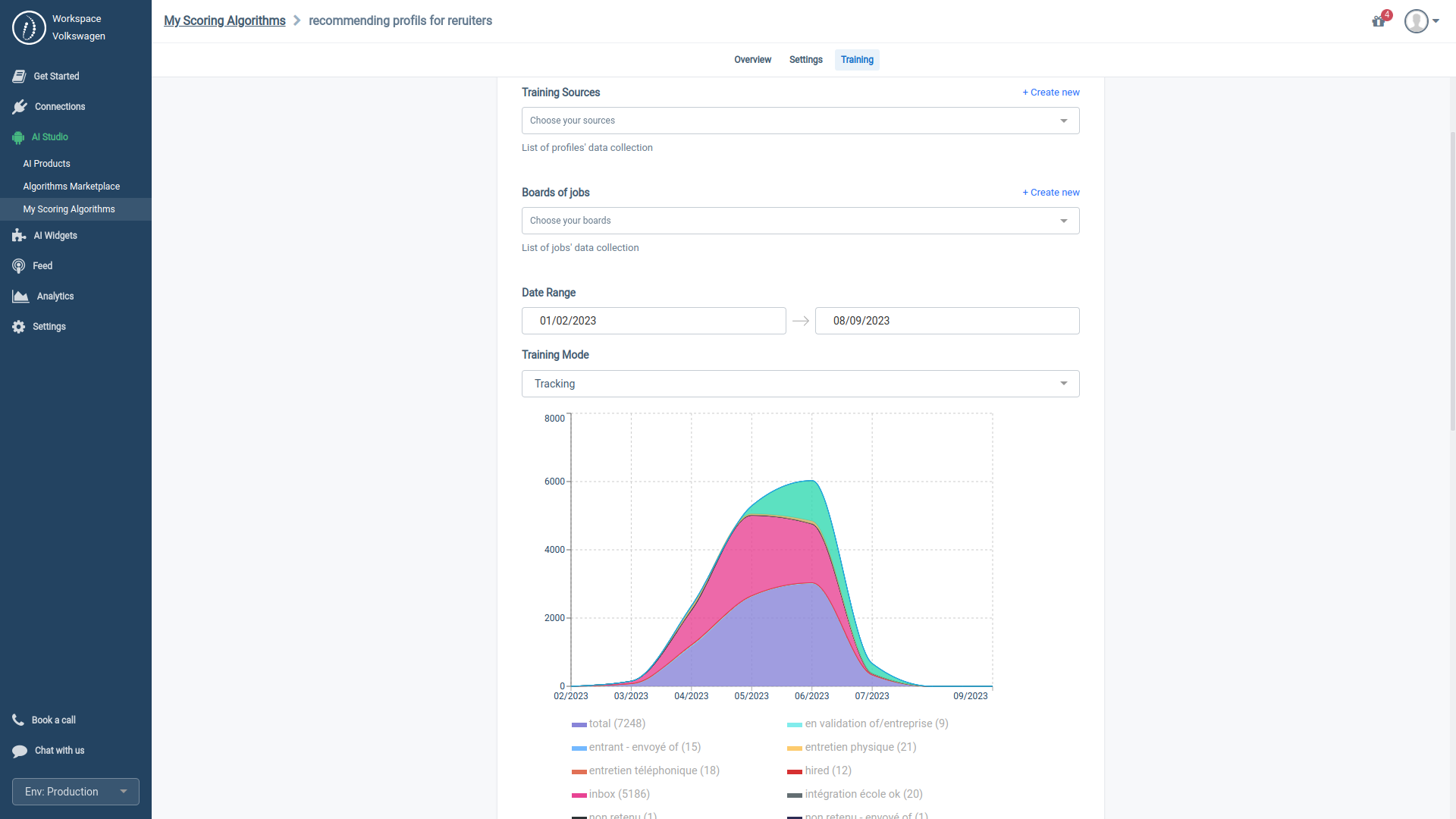
Our Visual Studio enables you to categorize each stage of your user journey as positive, neutral, or negative.
We've designed our visual builder with our philosophy that a hiring process or talent experience is akin to a train line. Candidates can exit at any stage (considered a negative outcome), and the aim is to help each candidate progress as far along the journey as possible, ultimately to the final stage (considered a positive outcome).
Our Scoring algorithms align with this same objective, optimizing the candidate's progression through each phase of their journey.
4.4. Launching your Training
Once you've verified that your dataset has a sufficient quantity and quality of labels, the next step is to initiate the training process for your Scoring algorithm.
Once you've initiated the fine-tuning task, our servers may take time to finish it. Your training task might be in a queue behind other tasks, and the actual training can range from minutes to hours, depending on the size of your dataset.
After completing the training, we highly recommend evaluating your Scoring Algorithm's performance and fairness, as detailed in the next section, before using it.
In your Scoring Algorithm's "Overview" tab, you can easily switch between previous versions and roll back to one that performs best for you.
4.5. Estimating Fine-tuning Costs
There are no additional charges for training since we offer limited training resources. We process one training model at a time, so your job may be placed in a queue depending on other ongoing training tasks.
5. Evaluation & Compliance
5.1. Introduction
At HrFlow.ai, we believe that Artificial Intelligence's full potential for societal benefit can only be realized if it is safe and predictable. While advanced AI models offer immense promise for fixing the labor market and improving many aspects of human life, businesses and governments must manage the accompanying risks proactively.
In the following sections, we'll outline our approach to AI safety and some of its reasoning, aiming to contribute to the broader conversation on AI safety and progress within the HR sector.
5.2. Current Regulatory Landscape
In early 2018, we were pioneers in raising awareness about AI risks in recruitment. We kickstarted public dialogues and publications while collaborating with the French Regulator (CNIL) and Facebook's Startup Program on AI Regulation and Data Protection.
Read our paper from May 2018: https://blog.hrflow.ai/overcoming-recruitment-biases/
Despite the challenges posed by the rapidly evolving landscape of AI, regulators have made significant progress in keeping up with these advancements by introducing key measures, such as:
- 2018: The EU's General Data Protection Regulation
- 2019: CNIL's guidelines on AI within the scope of GDPR compliance,
- 2022: NYC’s anti-bias law for hiring algorithms
- 2022: The USA's AI Bill of Rights,
- 2023: The EU's proposal for a regulatory framework on artificial intelligence.
Most AI regulatory frameworks define four levels of risk in AI.
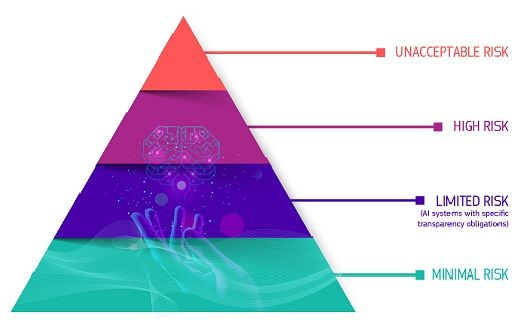
Most AI regulations categorize AI applications within the Recruiting and Talent Management sector as high-risk AI systems. Before these high-risk AI technologies can be introduced to the market, they need to fulfill the following requirements:
- Requirement 1: Purpose and Documentation of the AI system
- Requirement 2: Appropriate Human Oversight Measures
- Requirement 3: Clear and Adequate Information to the User
- Requirement 4: High Quality of Datasets
- Requirement 5: High Level of Robustness, Security, and Accuracy
- Requirement 6: Adequate Risk Assessment and Mitigation Systems
- Requirement 7: Logging of Activity & Traceability
In the upcoming sections, we will concisely overview our approach to AI safety and performance. Additionally, we'll highlight critical product updates released this fall aimed at making our AI algorithms more user-friendly for both HR professionals and HR software providers.
5.3. Compliance-Centric Design
At HrFlow.ai, we've implemented a compliance-centric design for our platform aimed at fulfilling the regulatory requirements for all stakeholders:
- Admins: Such as IT and HR Departments, HR Software Vendors, and Regulatory Bodies
- Users: Including Job Seekers, Candidates, Employees, Recruiters, and Managers
5.3.1. Governance
Admins maintain complete control over AI models via their HrFlow.ai Workspace. The platform provides visibility into performance and fairness metrics, as well as processes, enabling customers and regulators to evaluate the compliance of our scoring algorithms with applicable laws and guidelines. This functionality empowers our customers to satisfy Requirement 1 regarding the Purpose and Documentation of the AI system in the event of an audit.
5.3.2. Consent & Guidance
Our Scoring algorithms and AI Copilots aim to provide well-informed recommendations instead of fully automating decisions. This methodology complies with Requirement 2 for Appropriate Human Oversight Measures, as it is executed by the end beneficiaries of the AI— the users.
HrFlow.ai offers three key features to help customers comply with Requirement 3, ensuring Clear and Adequate Information is provided to users:
- Upskilling API: Introduced in 2018, this Explainable AI (XAI) module works with our Scoring API to elucidate every recommendation. A frequent use case is identifying and addressing skill gaps between a candidate's profile and a specific job role.
- Algorithmic Consent: This feature lets users opt for either AI-powered or manual processing for their user experience. While manual processing is an option, we recommend activating AI to improve your chances of a positive result. Specifically, our Scoring models increase the likelihood of a successful job match in a hiring scenario with a high volume of applications and open positions.
- Privacy Consent: This feature allows users to dictate how their career data and feedback are utilized. They can opt to keep it private, use it solely for personalizing their recommendations, or contribute to improving the overall user experience.
5.4. Training Data Evaluation
To minimize "Representation Bias" and prevent skewed outcomes, we implemented the following steps during Cerebro's pre-training:
- Vetting the sources and employing techniques to clean and standardize the datasets
- Ensuring that our datasets accurately represent the diverse range of job seekers, candidates, employees, recruiters, managers, teams, industries, and locations.
To avoid affecting Cerebro's pre-trained model weights during fine-tuning, we use a strict procedure for handling customer fine-tuning data:
- Debiasing Workflow: Eliminates low-quality or risky data elements.
- Balancing Workflow: Modifies the dataset to ensure equal representation across all clusters or classes.
- Data Anonymization: Strips away all personal identifiers to reduce the risk of overfitting based on variables like location, ethnicity, gender, age, or stereotypes.
- Dataset Segmentation: Divides the fine-tuning data into separate training and validation sets.
- Quality Assurance Check: Confirms the dataset's sufficiency for fine-tuning the weights of the pre-trained Cerebro model.
Our training data processes allows our customer to meet Requirement 4 for High-Quality Datasets.
5.5. Pre-Deployment Assessments:
As stated in the section above, we automatically split fine-tuning data into a training and test portion.
We provide statistics on both :
- During the course of training: as an initial signal of how much the model is improving
- After the training is complete: to allow you to conduct a thorough evaluation before using the model in production
The metrics we provide are divided into two categories:
- Performance and Safety metrics aligned with Requirement 5 for achieving a High Robustness, Security, and Accuracy Level.
- Fairness and Accountability metrics, fulfilling Requirement 6 for Adequate Risk Assessment and Mitigation Systems.
5.5.1. Performance and Safety Metrics
To check the Performance and Safety metrics, simply :
- Go to the "My Algorithms" section
- Click on your specific algorithm's name
- Then, Select the "Performance and Safety Metrics" section under the "Overview" tab
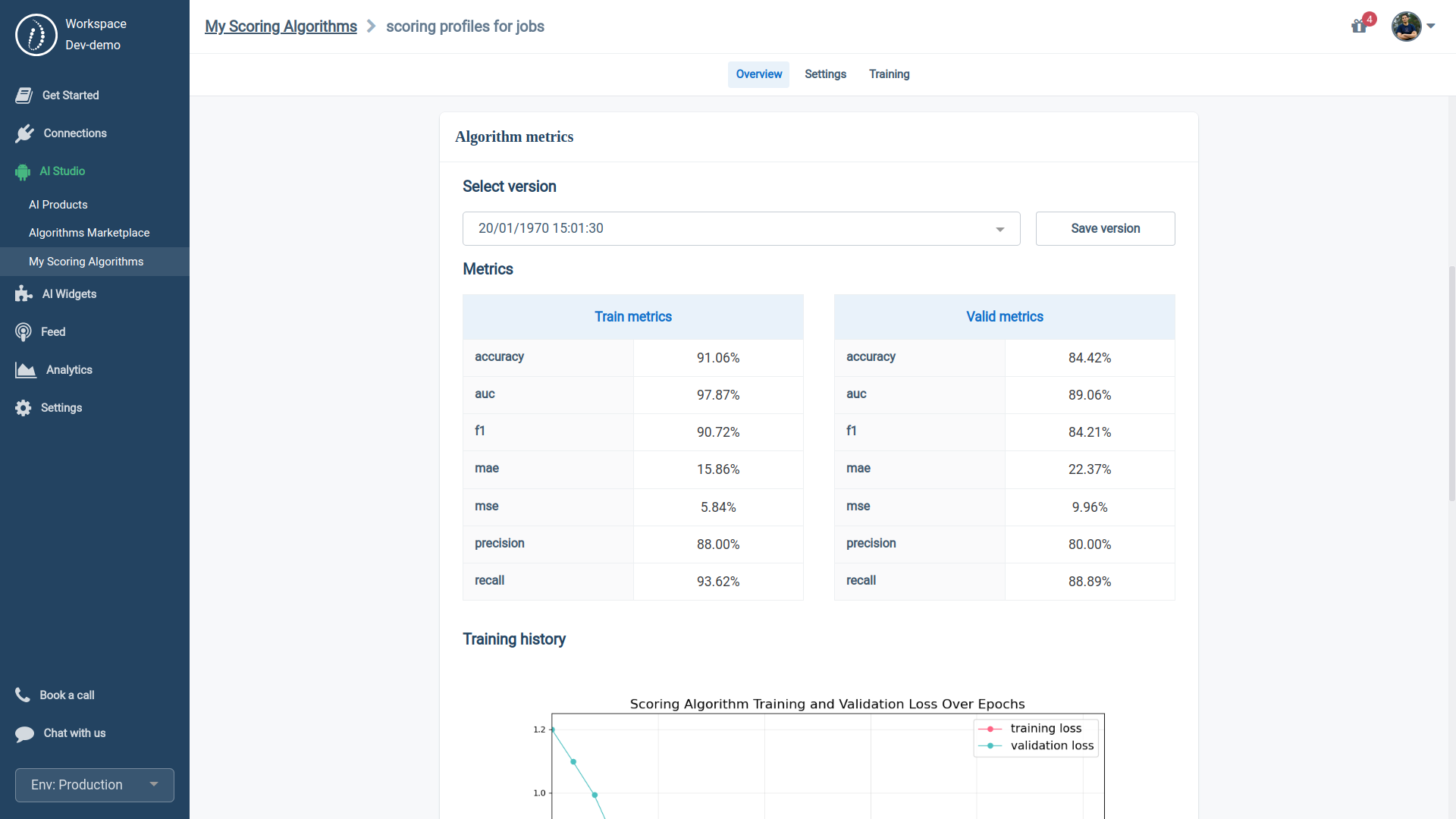
In this section, you can easily switch between the different trained versions of your Algorithm and make informed decisions based on both:
- Training metrics: indicate how well the model learns from its training data.
- Validation metrics: show how well the Algorithm can apply what it's learned to new, unseen data.
5.5.1.1. Basic Performance Metrics
- Accuracy: represents the percentage of correctly predicted samples. Negative samples should be predicted as negative, and positive samples should be predicted as positive. The higher the accuracy, the better the model's performance.
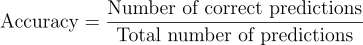

- Precision: This is the ratio of true positive predictions to the total number of positive predictions (true positives + false positives). It indicates the model's ability to avoid false positives. Higher precision indicates fewer false positive predictions.

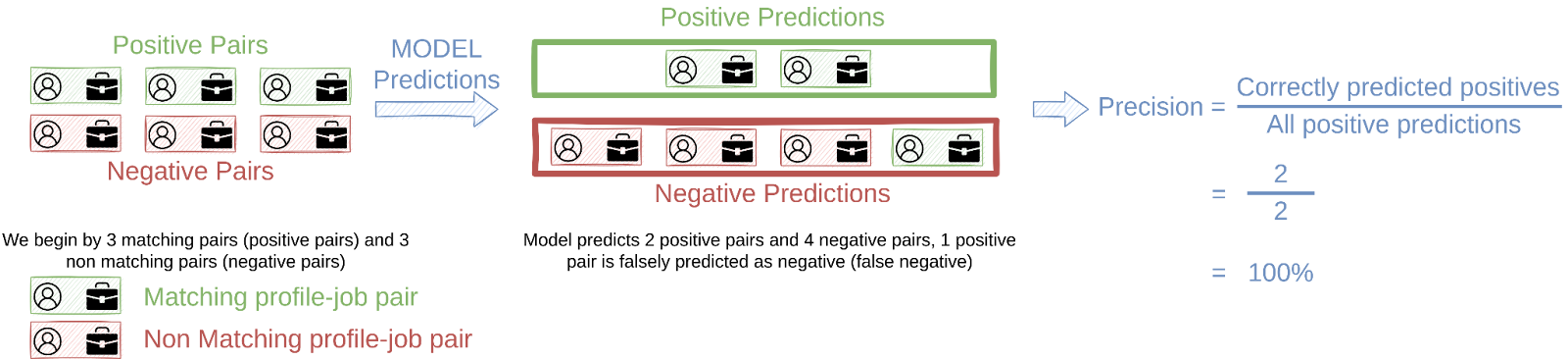
- Recall: or Sensitivity is the ratio of true positive predictions to the total number of actual positives (true positives + false negatives). It represents the model's ability to identify all positive samples. Higher recall indicates fewer false negatives.
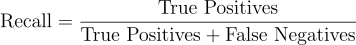

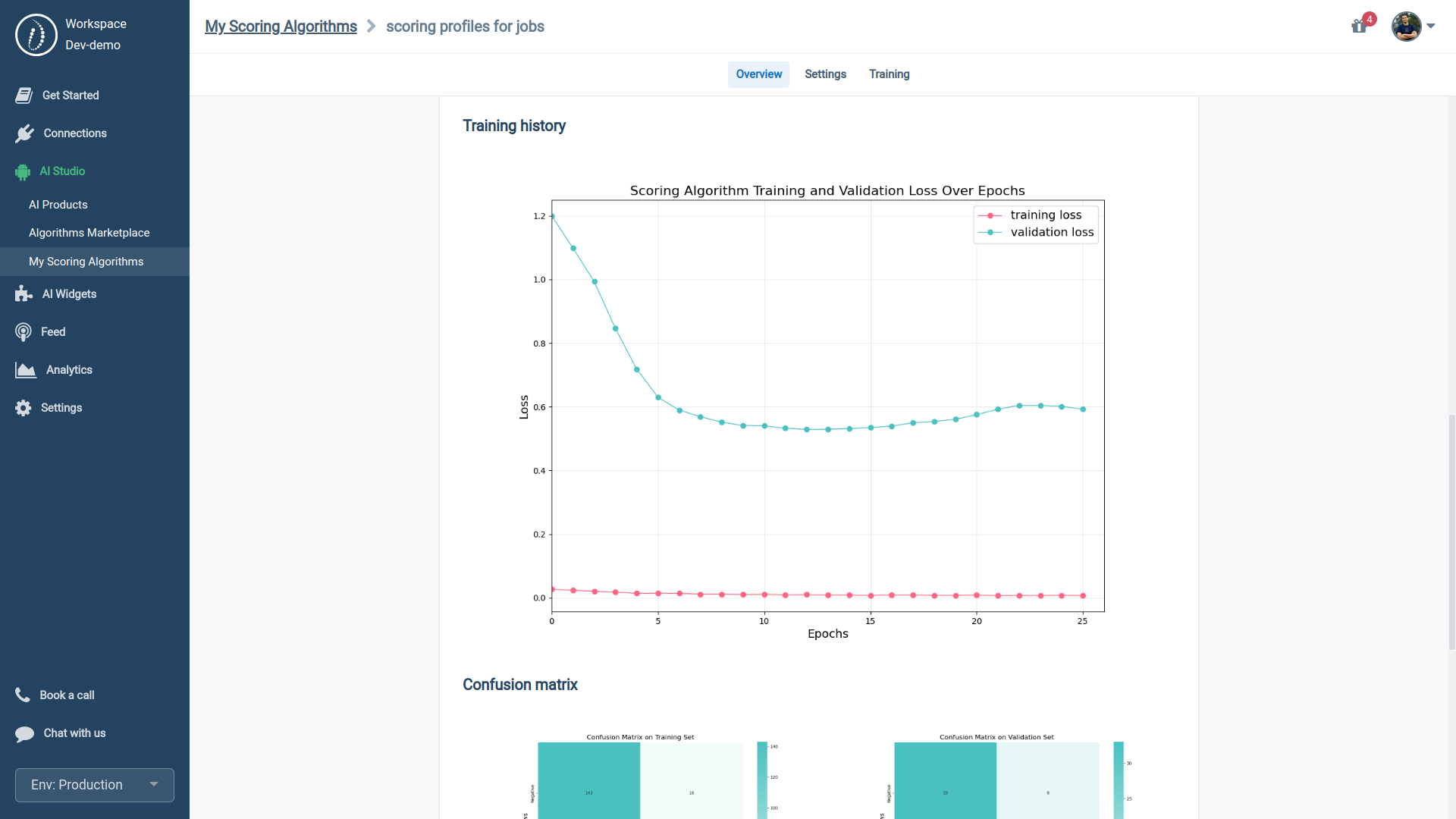
- Confusion Matrix: A confusion matrix is a 2x2 table that breaks down the performance of a classification model into True Positives, True Negatives, False Positives, and False Negatives. It's crucial for understanding the model's accuracy and reliability.

- Loss curves: These are the error rate metrics that the model is trying to reduce by learning from the data given your conversion goal. The lower the number, the better the algorithm is at its job. A low loss on the validation dataset suggests the model is reliable and better at generalization and not just memorizing the training data.
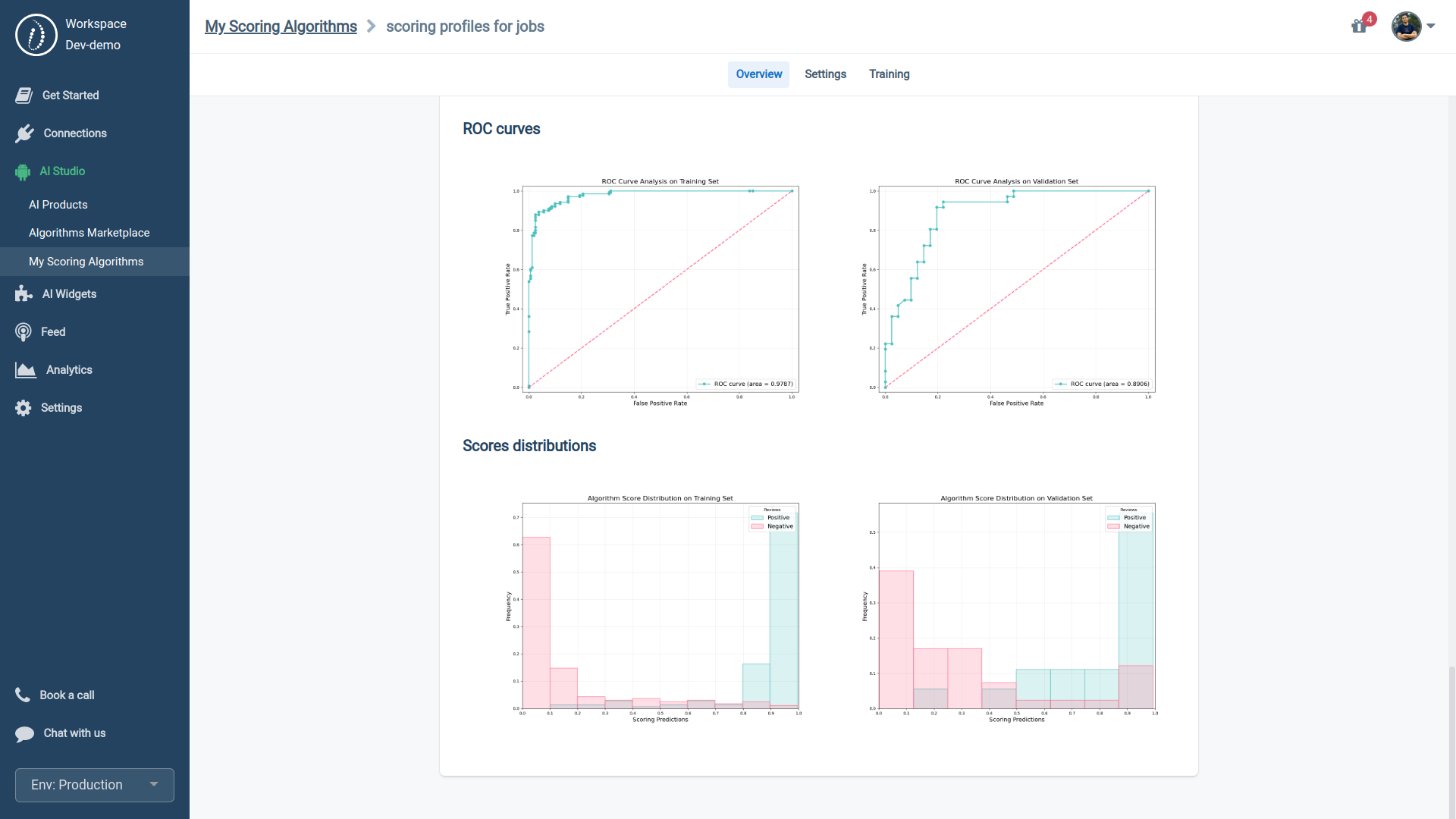
- Scores' distribution: The score distribution curve visually represents the model's ability to separate positive and negative cases accurately. True positives are marked in green and should ideally approach a score of 1, while true negatives appear in red and should be close to 0. A clear gap between the green and red zones demonstrates the model's effectiveness.
5.5.1.2. Advanced Performance Metrics
- F1 Score: The F1 score combines precision and recall into a single metric that evaluates the model's performance. It is the harmonic mean of precision and recall, providing a comprehensive assessment of false positives and negatives. A higher F1 score indicates a better balance between precision and recall.
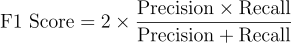
- MAE (Mean Absolute Error): MAE is the average of the absolute differences between predicted and actual outcomes. It provides a measure of the magnitude of the error but does not indicate its direction.
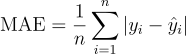
- MSE (Mean Squared Error): This is the average of the squares of the differences between predicted and actual values. It penalizes larger errors more than smaller errors.
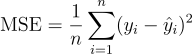
- ROC (Receiver Operating Characteristic): a graph that shows how well a binary classification model separates classes.
- AUC (Area Under the Curve): is the area under the ROC curve that measures the model's effectiveness—the closer to 1, the better.
5.5.2. Fairness and Accountability Metrics
To check the Performance and Safety metric, simply :
- Go to the "My Algorithms" section
- Click on your specific algorithm's name
- Then, Select the "Fairness and Accountability metric" section under the "Overview" tab
In the "Fairness & Accountability Metrics" section, we offer two assessments t to ensure your fine-tuned algorithms are low-risk and unbiased. You can compare two key metrics:
- Data Fairness, which reveals any undesired patterns in your historical data
- Model Fairness, which indicates how well the algorithm corrects historical data biases.
This dual assessment helps you to pinpoint past mistakes and proactively prevent them from reoccurring in the future.
In our training and evaluation processes, we monitor six specific types of potential biases:
- Gender-related bias: Discrimination based on gender affects how candidates are evaluated.
- Ethnicity bias: Unfair treatment or categorization based on ethnicity, impacting recruitment or promotions.
- Stereotype bias: Making assumptions based on social or cultural stereotypes, affecting objective decision-making.
- Age-related bias: Discrimination based on age, potentially sidelining younger or older candidates.
- Location bias: Preference or disadvantage based on geographical location, affecting remote, local candidates or lower socioeconomic areas.
- Overload bias: Discrimination resulting from high application volumes, leading to rushed or stressed decisions.
5.6. Post-Deployment Monitoring
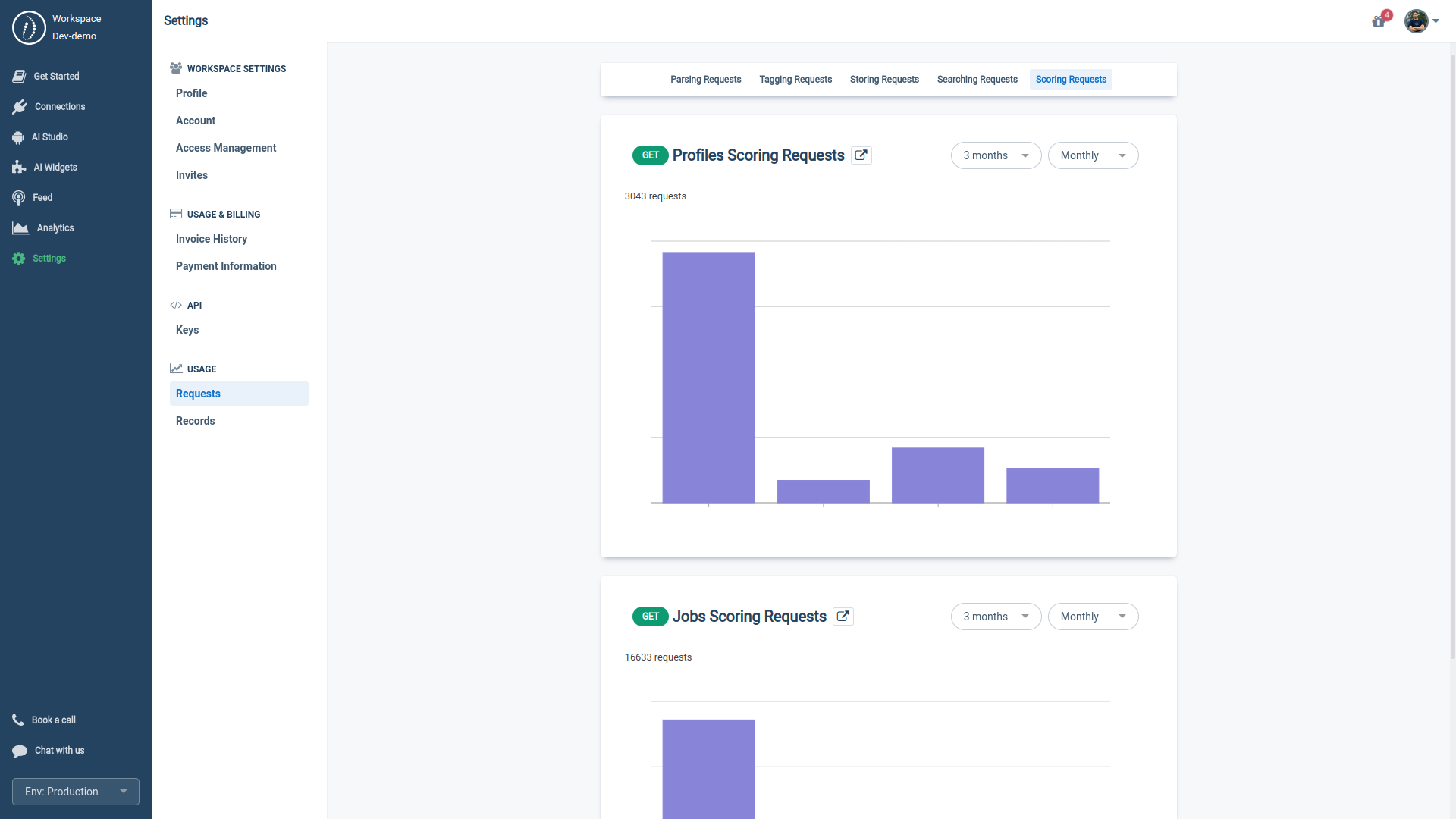
To enhance traceability and meet Requirement 7, we provide our customers with a real-time monitoring dashboard. This tool allows for comprehensive tracking of all API requests and data records, ensuring end-user activities—such as job seekers, candidates, recruiters, employees, and managers—are easily auditable.
Cerebro has been officially announced during the International Conference on Machine Learning (ICML2023) in Hawaii by our CEO, Mouhidine SEIV.
This event is well-known for presenting and publishing cutting-edge research on machine learning and its closely related fields, including artificial intelligence, statistics, and data science.
With its 4 Billion parameters model, unmatched adaptability, and bias-mitigation measures, Cerebro is poised to revolutionize the future of recruitment practices.
