
Introducing Fairness by design
29th January 2018, Talk at Serena Capital: Overcoming the recruitment Biases // Mouhidine SEIV, CEO of Riminder
Programming Vs. Machine Learning
As Below, to get computers to do something new we used to program them.
Programming required laying out detailing every single step and action in order to achieve our new goals.

Now, even if you don’t know how to describe a certain problem, you can teach a computer how to solve it through Machine Learning.
Machine learning algorithms provide a computer with the ability to automatically learn and improve itself from experience only by drawing examples from the data. The more data and computation power they can access, the better they get.
Machine Learning Vs. Deep Learning
Deep Learning is an area of Machine Learning based on networks of simulated neurons inspired by how the human brain works. As a result, Deep Learning algorithms have no theoretical limitations and allow computers to outperform traditional Machine Learning algorithms and even human performance in specific tasks.
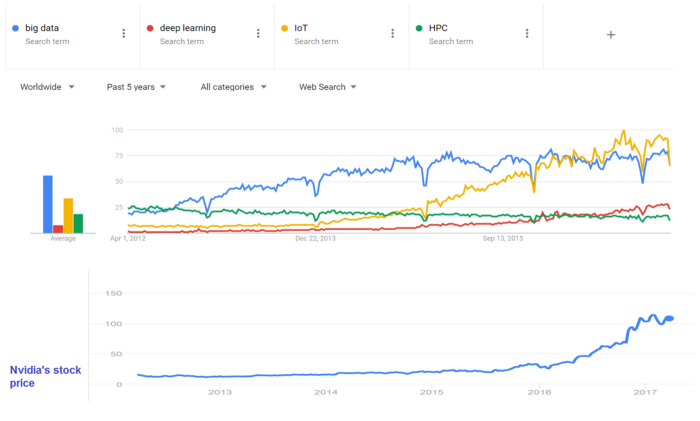
In 2006 Deep learning techniques started outperforming traditional Machine learning techniques — first in Speech and Image, then Natural Langage Processing, for two primary reasons:
- Better benefit from the large amounts of data than ML techniques
- Faster machines and multicore CPU/GPU (NVIDIA) allowed both the usage of DL algorithms in production but also the emergence of new models and ideas through iterations.
Microsoft Demo Speech Recognition System before (2006) and after (2012) Deep Learning
Most importantly Deep Learning algorithms allow better leverage of unstructured data by engineering their features and representations to achieve a given goal without requiring any prerequisites about the data field from the Developers who are training them.
An impressive example was the Kaggle competition won by a team of Geoffrey Hinton about automatic drug discovery — beating all the international academic community with no background in chemistry, biology, or life sciences, all in just two weeks!
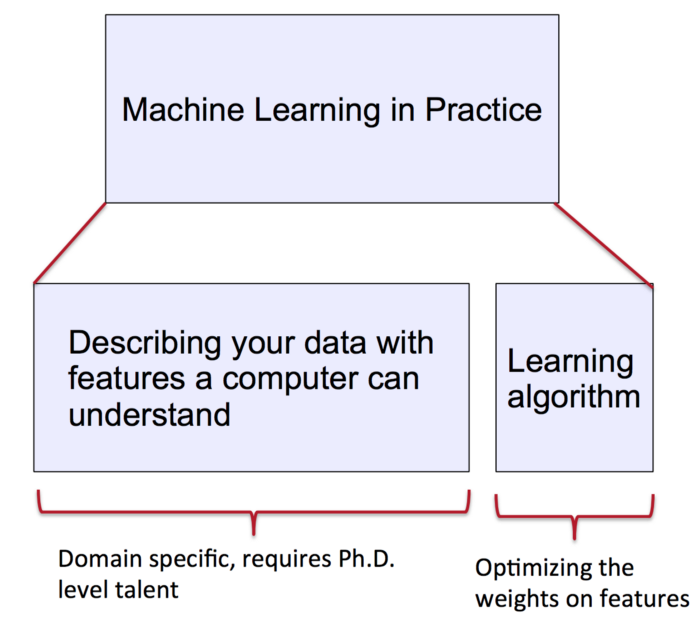
The trouble with Learning Systems
Learning systems are rapidly expanding into many areas of everyday life from healthcare to education. Amongst the excitement about these large-scale data systems, two major concerns are arising:
> A conscious one: Adversarial Examples.
> An unconscious one: Bias
Adversarial Examples, the conscious trouble
“Adversarial examples are inputs to machine learning models intentionally designed by an attacker to cause an incorrect output prediction from the model. They are to machines what “optical illusions” are to human.
For instance by adding a small and well-calculated noise/perturbation to any image you can completely change the original prediction of a model with a high confidence.

Even worse a malicious hacker can leverage these weaknesses to fool a Learning Model and take control of your future self-driving car making it blind to pedestrians’ presence on roads.
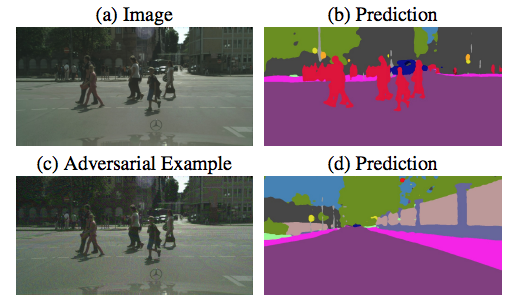
Recent research has shown adversarial examples can still fool a system even after they have been printed.

A recent paper shows that humans are not different from computer systems and that real-life adversarial examples can fool humans too.
You can read more about adversarial examples here: https://blog.openai.com/adversarial-example-research/
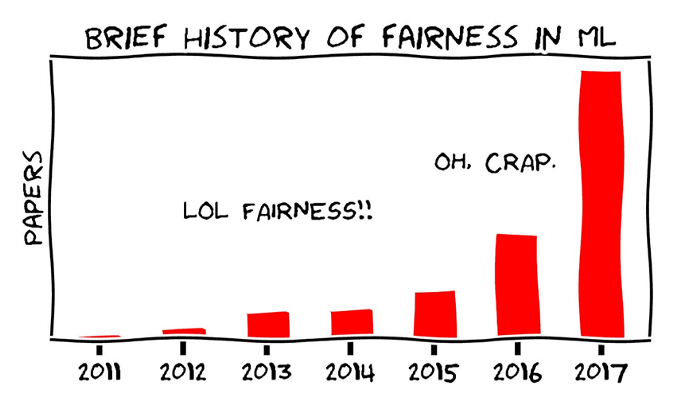
Bias, the unconscious trouble
The definition of the word “Bias” has been changing over the last centuries :
- 14th century: Geometry diagonal line
- 19th century: Law, undue prejudice
- 20th century: Statistics, systematic difference between a sample and a population.
Bias in machine learning
Machine Learning systems are keeping on being integrated into the life of millions of people every day. Thus, the research on Machine Learning Bias is wholly justified.
In machine learning, the bias is commonly visualized:
- trough “under-fitting” which corresponds to a situation with “high bias & low variance”
- in contrast with “over-fitting”, a situation of “low bias & high variance”.
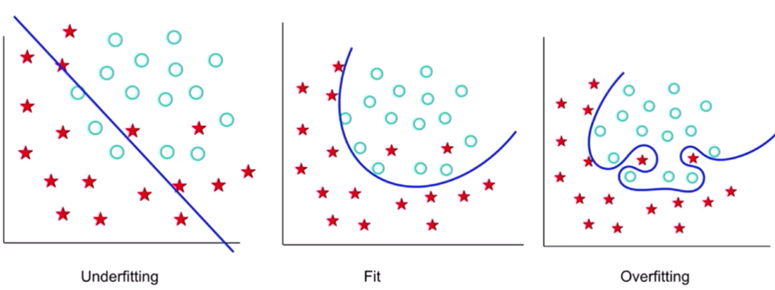
Bias beyond machine learning
Considering the Bias problem in Machine Learning as a purely technical problem leaves out a whole part of the picture.
Training data is often biased by the world large history of human undue prejudices. As a consequence, this introduces a new intrinsic bias (legal) in the learning systems that cannot be solved even with model validation techniques. As consequence, Machine Learning models can still be biased from a legal perspective while being unbiased from a technical standpoint.
Recruitment, a practical use-case
Even with the best intentions, it’s impossible to separate humans from their own biases.
In recruiting, most biases occur and are perpetrated mainly because of the use of Keyword search Engines to screen candidates. Indeed, since these keyword systems are hard to tune, most people end up typing well-known schools and well-known companies which favor prestige over the real potential of the candidate. Furthermore, because these tools are not smart enough to translate a diverse set of experiences and backgrounds they :
> overlook the majority of high potential candidates
> reveal false positives.
Revealing people full potential
At Riminder, we believe that the main challenges that recruiters are facing today and will be facing in the next decades are:
- handling the increasing diversity of talents ( mainly with talent globalization and the career path diversity )
- keeping up with the rapidly changing job landscape ( +60% of the jobs that we need in the next 20 years do not exist yet, source: McKinsey).

By eliminating bias, in recruitment we allow businesses to identify 3x times more relevant talent within their existing databases while cutting 1/2 the time to fill a position.
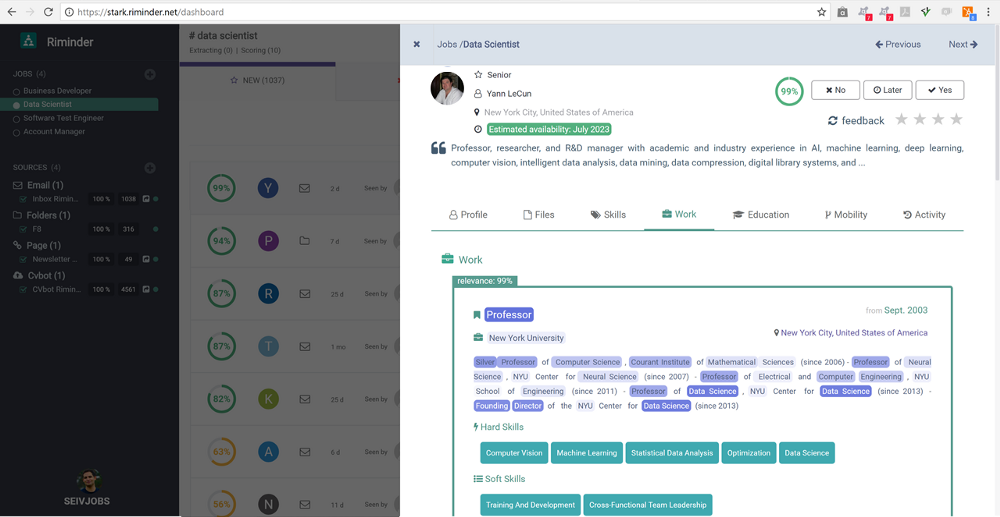
By qualifying (parsing+enriching+scoring) every element of the career path of the candidate (namely the working experiences, projects, educations, hard skills, soft skills, transitions, etc.) we identify the overlooked connections between positions.
At the opposite of a keyword system, for which a “sous-chef” and an “ event manager” are unrelated, our technology understands the hidden correlations between them — such as being highly organized and being able to perform well under pressure.

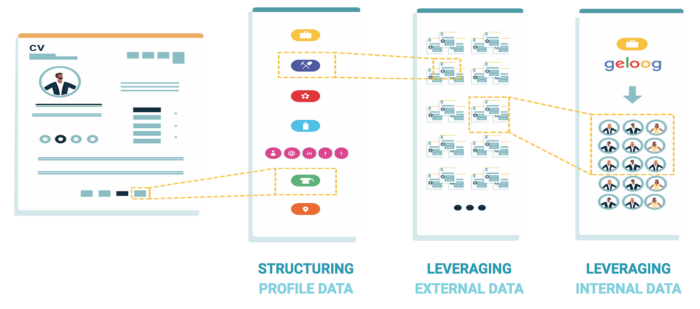
Riminder.net AI Technology
Our technology is based on 4 layers of AI:
- First Parsing: we use Deep Computer Vision and Natural Language Processing to parse each resume as a structured data profile.
Learn more: https://blog.hrflow.ai/hr-software-companies-why-structuring-your-data-is-crucial-for-your-business/ - Second Enrichment+ Scoring: on top of this structured data, we built a general layer based on the millions of career paths we analyzed
- Third Custom Scoring: a custom layer based on the internal data of the company and feedback from the recruiters to fit its specific needs regarding culture and requirements.
- Fourth Revealing: explaining the evidence behind every recommendation taken by our algorithms.
Quick tips for candidates that are applying to companies that are not using Riminder:
>Language bias: always send a resume in the most commonly used language in the company. People focus on the language that is the easiest for them.
→Interview likelihood: +6.8%.
>Layout bias: always send a one-pager mono-column with a maximum of 2 text colores resume. People focus on the layouts that is the easiest to read.
→Interview likelihood: +N columns= -3.2% x N and +N pages = -3.8% x N.
Mathematical Notions of Fairness
Fairness of Allocation
Fairness can be measured using a variety of metrics, among which are:
- Statistical Parity: belonging to a subgroup of a large community should not change the outcome of a classifier.
- Individual Fairness: Ensures that if two individuals are similar according to metric the outcome of the prediction should follow that metric.

- Equality of Opportunity: Persons that are fully qualified for an outcome shouldn’t see their outcome changing based on their belonging to a subgroup.
- Predictive Parity: If a classifier had favored an outcome for a subgroup, the hypothesis should be true in the real life.

Those definitions of fairness and parity are not exhaustive.
A recent research paper shows that they are fundamentally in conflict and cannot be satisfied simultaneously.

Word embeddings are widely used in Natural Language Processing to represent words syntactically and semantically.
They have an interesting linear property that allows
→ vector(man) — vector(woman) = vector(king) — vector(queen) .
→ vector(man) — vector(woman) = vector(men) — vector(women) .
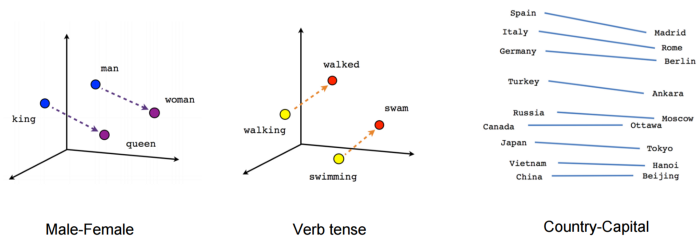
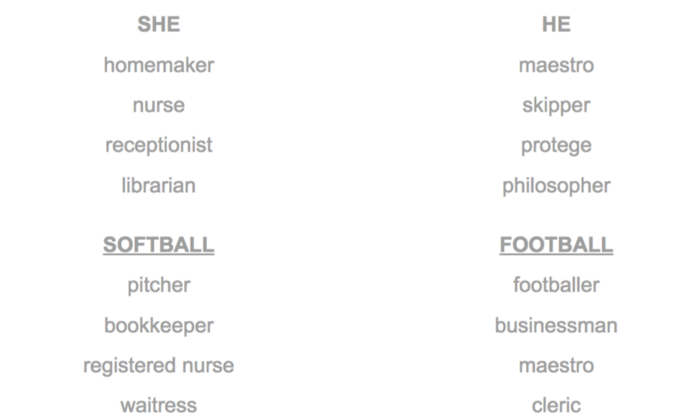
Besides their efficiency Word embeddings can propagate some very dangerous biases based on the training data — such as Gender Stereotyping:
→ vector(man) — vector(woman) = vector(developer) — vector(designer) .
Debiasing word embeddings
There are two types of Gender Stereotyping:

A recent paper, available, introduced a novel approach to de-bias Word Embeddings using Crowdsourcing.
Here is briefly how would take it away, with our previous gender bias example:
>First: Gather all words X and Y words of the vocabulary such as:
→ (i) vector(she)-vector(he) ≈ vector(X)-vector(Y)
→(ii) X-Y is an unappropriated gender stereotype
>Second: Build a matrix W of the (X-Y) pairs.
>Third: Take the singular value decomposition of W to find the subspace corresponding to gender stereotyping. Most of the time, these singular values are very skewed, and it is easy to select the top one or the top two singular vectors to represent this bias subspace.
>Fourth: Apply the bias correction:

Word Embedding De-biasing Results:
— Reduced gender stereotyping in the word embeddings
— Performance on downstream tasks still almost the same
Main takeaways:
>Supervised learning:
— Maximize the accuracy of a classifier subject to fairness constraints
— Retrain the classifier to satisfy fairness constraints.
>Unsupervised learning:
— Ensure features learned are not propagating training data biases.
More resources about Deep Learning:
We recently launched a series of courses in Deep Learning from theory to deployment: https://github.com/Riminder/deep-learning-practical-course
> Course 1 (05–04–18):
— Introduction to Deep Learning — Mouhidine SEIV (Riminder)
> Course 2 (12–04–18):
— Deep Learning in Computer Vision — Slim FRIKHA (Riminder)
> Course 3 (19–04–18):
— Deep Learning in NLP — Paul COURSAUX (Riminder)
> Course 4 (02–05–18):
— Introduction to Deep Learning Frameworks — Olivier MOINDROT (Stanford)
> Course 5 (10–05–18):
Efficient Methods and Compression for Deep Learning — Antoine BIARD (Reminiz)
> Course 6 (17–05–18):
— Deployment in Production and Parallel Computing — INVITED GUEST
More ressources about Fairness in Machine Learning
>Measuring and Mitigating Unintended Bias in Text Classification (Dixon et al., AIES 2018)
— Exercise demonstrating Pinned AUC metric.
>Mitigating Unwanted Biases with Adversarial Learning (Zhang et al., AIES 2018)
— Exercise demonstrating Mitigating Unwanted Biases with Adversarial Learning.
>Data Decisions and Theoretical Implications when Adversarially Learning Fair Representations (Beutel et al., FAT/ML 2017).
>No Classification without Representation: Assessing Geodiversity Issues in Open Data Sets for the Developing World (Shankar et al., NIPS 2017 workshop)
>Equality of Opportunity in Supervised Learning (Hardt et al., NIPS 2016)
>Satisfying Real-world Goals with Dataset Constraints (Goh et al., NIPS 2016)
>Designing Fair Auctions:
— Fair Resource Allocation in a Volatile Marketplace (Bateni et al. EC 2016).
— Reservation Exchange Markets for Internet Advertising (Goel et al., LIPics 2016).
>The Reel Truth: Women Aren’t Seen or Heard (Geena Davis Inclusion Quotient)
What’s next for you?
- Visit our website: https://hrflow.ai
- Learn more about our product: https://help.hrflow.ai
- Check out our uses-cases: https://hrflow.ai/use-cases
- Discover our latest updates: https://updates.hrflow.ai/
Are you a Developer?
You can start now using our self-service API without any painful setups.
Get started in a few minutes with our documentation:
https://developers.hrflow.ai