Last month our team hosted our first monthly Product Live demo to share with the HR IS community our latest updates and achievements.
In the case you missed the first edition, we already started publishing replays from the webinar:
Nowadays, an increasing number of Corporates, Governments and HR Software Vendors are trying to implement machine learning models to address HR challenges.
1. At the training time:
- Unsecure access to their own data ⇽ lack of integration between internal tools
- Small amount of samples ⇽ lack of HR Data infrastructure
- Biased datasets ⇽ constantly changing policies & historical processes (Overcoming Recruitment Biases 2018: https://medium.riminder.net/overcoming-recruitment-biases-1e68cdd82405)
- Industry mismatch ⇽ when using open-source general-purpose vectors
- Long R&D time ⇽ Multiple year without a guarantee
- Training costs ⇽ Huge models & too slow epochs (>5 million $ to train the latest state-of-the-art auto-regressive language models, aka GPT-3)
- ...
2. At the inference time:
- Generalization to new profiles or jobs ⇽ Fast-moving labor market
- Inference costs ⇽ Huge models (RAM) & slow predictions (GPU heavy)
- Deployment costs
- ...
Today, I'm very happy to dedicate this article to the part 4 of our latest webinar tackling the above issues.
This tutorial is highlighting our brand-new feature the "Embedding API".
It has been specially designed for Data Science teams working on HR Data challenges.
We have been polishing it since early 2017. It was meant originally for internal usage at HrFlow.ai (ex: Riminder.net). But we decided to make it publicly available as a contribution to the community to lift the load of research teams.
If you're already using our "Parsing API", you can request now free access here.
Focus on building quickly highly accurate models, not engineering features
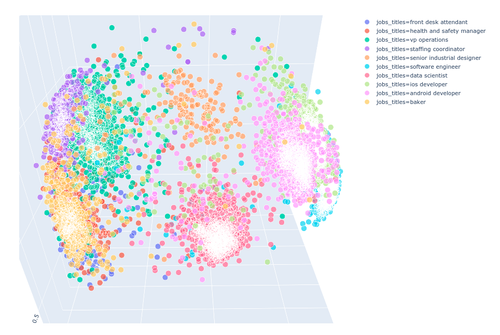
The Embedding API analyzes the output of the Parsing API (and optionally the Revealing API) to return numerical vectors representing a profile, a job or an HR document section in a 1024-dimensional space. The vectors of similar objects will be close to each other.
Some advantages:
- Saving up to 90% of R&D time
- Training with a limited amount of labels
- Increasing inference speed up to 26x
- Limiting the memory footprint on production up to 300x
- Multilanguage support (+32 Lang)
- Multitask representation
- Hierarchical HR Data modeling
Since Python is the favorite programming language within the data Science community, this feature has been designed to be compatible with popular frameworks such as Tensorflow, Pytorch, Keras, Numpy and Pandas.
To install :
pip install hrflow
To import :
from hrflow import Hrflow
Example of Usage :
from hrflow import Hrflow
import base64
import numpy as np
def decode_float_list(base64_string, dfloat = np.dtype('>f4')):
""" Convert 64 string to numy vectors """
bytes = base64.b64decode(base64_string)
np_array = np.frombuffer(bytes, dtype=dfloat)
return np.reshape(np_array, (-1, 1024)).tolist()
# Init HrFlow client
client = Hrflow(api_secret="Your API Key", api_user="Your API user email")
# Provide a valid Profile Json
profile_json = {...}
# Retrieve the profile embedding in base64
response = client.document.embedding.post(
item_type="profile",
item=profile_json,
return_sequences=True)
vector = decode_float_list(response.get('data'))
Keep Reading
 Riminder
Riminder
#ai #hr #workflows #opensource #deeplearning #datascience #nlp #tensorflow #keras #pandas #pytorch