Benchmarking Resume Parsing Solutions : Daxtra, Sovren, Hireability, Textkernel and Segmentr (by Riminder)
If you are working in the HR software industry or a member of an HR department, you definitely have thought about structuring your CV data before. Projects requiring resume structuring can be crucial to your business and can range from simple user experience improvement to strategic product roadmap advancements. These are some examples of the common use cases of CV structured data in the HR Software Industry:
- Creating an efficient and relevant talent search experience
- Getting market-relevant insights about your talent pools
- Building usable datasets for an AI based job matching tool
Now you can parse all your resumes, no exception made!
Resume Parsing, the inevitable solution to your problem
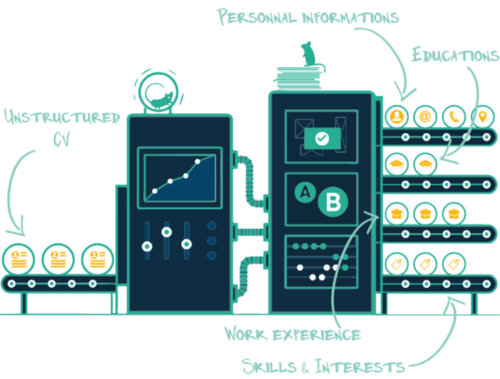
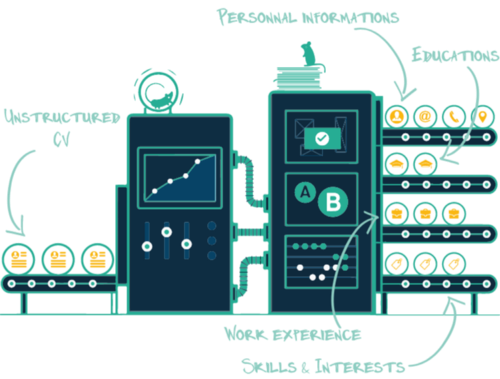
A resume parsing solution is a software that takes a resume as an input that can be in any media format (PDF, Word or Image) or template, then convert it into a structured data format readable by the computer — such as XML or JSON.
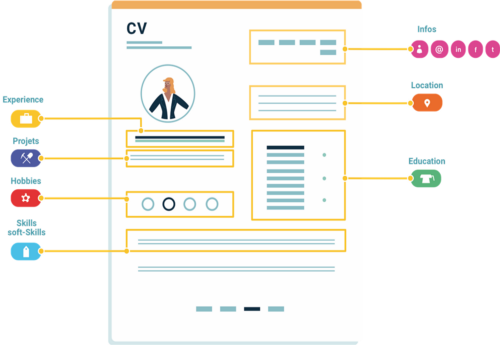
The information that is extracted by a resume parser usually includes the following:
- personal information: name, email, address, phone
- list of experience: start date, end date, location, job title, company, description, …
- List of education: start date, end date, location, degree, university …
- List of skills, …
- List of interests
Seems easy? But the reality is hard!
The reality is almost no meaningful improvement for more than 10 years
The first resume parsers were born in the late '90s to provide a data structuring technology to HR software companies that are looking for a stand-alone packaged solution in order to focus on their core business. Some of these first-mover solutions are:
- Sovren (1996)
- TextKernel (2001)
- Daxtra (2002)
- …
Here are some few metrics:
+1.4 Billion resumes are parsed every year.
+40% of resumes have a complex layout (multi-column, etc.)
+7% of resumes are either scans or images
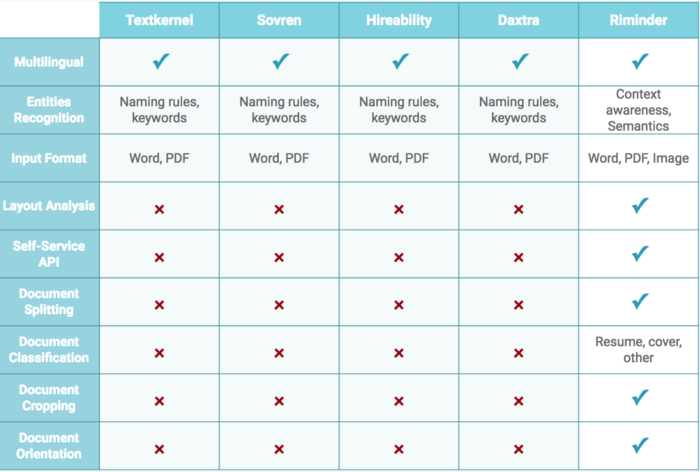
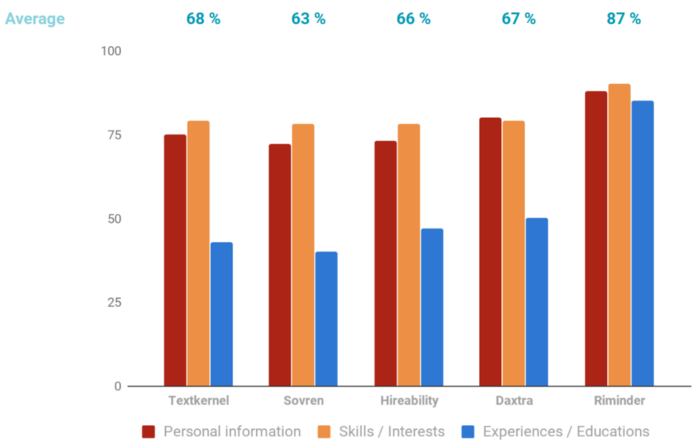
How Daxtra, Sovren, Hireability, Textkernel, and Segmentr (by Riminder) are doing at this task?
Building a general and reliable parser requires many different blocks.
For instance, the system should be able to handle:
- Complex layouts (ex: multi-column resumes, pictures with backgrounds, etc.)
- Ambiguous entities (ex: Facebook, as a former employer vs. a social media skill)
- Different media formats (PDF, Word, Image, etc.)
- Multiple languages
- ...
The following comparison between some of Segmentr’s features and previous generation existing resume parsing solutions is the result of extensive validation tests we led at Riminder with our Customers:
We’ve also computed the performance of each solution over a validation dataset of around 100 resumes randomly sampled. For each output, we averaged the accuracy obtained across the multiple labels. Below is a graph summarising the obtained results:
Segmentr example in python
First, you have to post your data using a POST REQUEST on following the endpoint below:
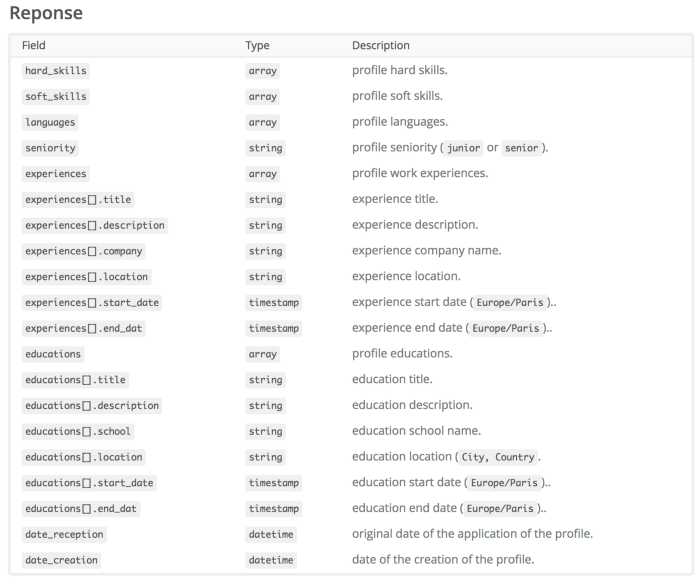
Here is the structure of the data that you’ll get:
What’s next for you?
Discover Segmentr Live
If you are interested to know more about Segmentr, you can book us for a demo: https://hrflow.ai/book-us.
You can also visit our https://labs.hrflow.ai to see AI applied to HR in action.
Are you a Developer?
You can start now using our self-service API without any painful setups.

Get started in a few minutes with our documentation
If you enjoyed this article, feel free to share it or reach out.
Follow us on Twitter @hrflowai
If you want to work on AI + FAIRNESS, check our jobs page;
